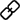400 128 6709

行业新闻
 发布时间:2023-07-06
发布时间:2023-07-06 点击次数:
点击次数: 近几年,图像生成领域取得了巨大的进步,尤其是文本到图像生成方面取得了重大突破:只要我们用文本描述自己的想法,AI 就能生成新奇又逼真的图像。
但其实我们可以更进一步 —— 将头脑中的想法转化为文本这一步可以省去,直接通过脑活动(如 EEG(脑电图)记录)来控制图像的生成创作。
这种「思维到图像」的生成方式有着广阔的应用前景。例如,它能极大提高艺术创作的效率,并帮助人们捕捉稍纵即逝的灵感;它也有可能将人们夜晚的梦境进行可视化;它甚至可能用于心理治疗,帮助自闭症儿童和语言障碍患者。
最近,来自清华大学深圳国际研究生院、腾讯 AI Lab 和鹏城实验室的研究者们联合发表了一篇「思维到图像」的研究论文,利用预训练的文本到图像模型(比如 Stable Diffusion)强大的生成能力,直接从脑电图信号生成了高质量的图像。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
 图片
图片
论文地址:https://arxiv.org/pdf/2306.16934.pdf
项目地址:https://github.com/bbaaii/DreamDiffusion
 Android 应用框架原理与程序设计36技pdf繁体版
Android 应用框架原理与程序设计36技pdf繁体版
Android应用框架原理与程序设计36技 pdf繁体版,书籍内容适用于Android 1.0,有些朋友可能对Android还不太熟悉吧?不知您是否听说过Google 在HTC定制的高端手机呢?其操作系统是基于Android的,如果还是不太清楚的话,可以Google一下“HTC g2”手机,可以大致了解一下手机操作系统的界面及架构特点。不管怎么说,Android手机编程目前还是主要面向高端,在将来可能会普及,因此Android编程还是很有必要掌握的。
 0
查看详情
0
查看详情

近期一些相关研究(例如 MinD-Vis)尝试基于 fMRI(功能性磁共振成像信号)来重建视觉信息。他们已经证明了利用脑活动重建高质量结果的可行性。然而,这些方法与理想中使用脑信号进行快捷、高效的创作还差得太远,这主要有两点原因:
首先,fMRI 设备不便携,并且需要专业人员操作,因此捕捉 fMRI 信号很困难;
其次,fMRI 数据采集的成本较高,这在实际的艺术创作中会很大程度地阻碍该方法的使用。
相比之下,EEG 是一种无创、低成本的脑电活动记录方法,并且现在市面上已经有获得 EEG 信号的便携商用产品。
但实现「思维到图像」的生成还面临两个主要挑战:
1)EEG 信号通过非侵入式的方法来捕捉,因此它本质上是有噪声的。此外,EEG 数据有限,个体差异不容忽视。那么,如何从如此多的约束条件下的脑电信号中获得有效且稳健的语义表征呢?
2)由于使用了 CLIP 并在大量文本 - 图像对上进行训练,Stable Diffusion 中的文本和图像空间对齐良好。然而,EEG 信号具有其自身的特点,其空间与文本和图像大不相同。如何在有限且带有噪声的 EEG - 图像对上对齐 EEG、文本和图像空间?
为了解决第一个挑战,该研究提出,使用大量的 EEG 数据来训练 EEG 表征,而不是仅用罕见的 EEG 图像对。该研究采用掩码信号建模的方法,根据上下文线索预测缺失的 token。
不同于将输入视为二维图像并屏蔽空间信息的 MAE 和 MinD-Vis,该研究考虑了 EEG 信号的时间特性,并深入挖掘人类大脑时序变化背后的语义。该研究随机屏蔽了一部分 token,然后在时间域内重建这些被屏蔽的 token。通过这种方式,预训练的编码器能够对不同个体和不同脑活动的 EEG 数据进行深入理解。
对于第二个挑战,先前的解决方法通常直接对 Stable Diffusion 模型进行微调,使用少量噪声数据对进行训练。然而,仅通过最终的图像重构损失对 SD 进行端到端微调,很难学习到脑信号(例如 EEG 和 fMRI)与文本空间之间的准确对齐。因此,研究团队提出采用额外的 CLIP 监督,帮助实现 EEG、文本和图像空间的对齐。
具体而言,SD 本身使用 CLIP 的文本编码器来生成文本嵌入,这与之前阶段的掩码预训练 EEG 嵌入非常不同。利用 CLIP 的图像编码器提取丰富的图像嵌入,这些嵌入与 CLIP 的文本嵌入很好地对齐。然后,这些 CLIP 图像嵌入被用于进一步优化 EEG 嵌入表征。因此,经过改进的 EEG 特征嵌入可以与 CLIP 的图像和文本嵌入很好地对齐,并更适合于 SD 图像生成,从而提高生成图像的质量。
基于以上两个精心设计的方案,该研究提出了新方法 DreamDiffusion。DreamDiffusion 能够从脑电图(EEG)信号中生成高质量且逼真的图像。
 图片
图片
具体来说,DreamDiffusion 主要由三个部分组成:
1)掩码信号预训练,以实现有效和稳健的 EEG 编码器;
2)使用预训练的 Stable Diffusion 和有限的 EEG 图像对进行微调;
3)使用 CLIP 编码器,对齐 EEG、文本和图像空间。
首先,研究人员利用带有大量噪声的 EEG 数据,采用掩码信号建模,训练 EEG 编码器,提取上下文知识。然后,得到的 EEG 编码器通过交叉注意力机制被用来为 Stable Diffusion 提供条件特征。
 图片
图片
为了增强 EEG 特征与 Stable Diffusion 的兼容性,研究人员进一步通过在微调过程中减少 EEG 嵌入与 CLIP 图像嵌入之间的距离,进一步对齐了 EEG、文本和图像的嵌入空间。
与 Brain2Image 对比
研究人员将本文方法与 Brain2Image 进行比较。Brain2Image 采用传统的生成模型,即变分自编码器(VAE)和生成对抗网络(GAN),用于实现从 EEG 到图像的转换。然而,Brain2Image 仅提供了少数类别的结果,并没有提供参考实现。
鉴于此,该研究对 Brain2Image 论文中展示的几个类别(即飞机、南瓜灯和熊猫)进行了定性比较。为确保比较公平,研究人员采用了与 Brain2Image 论文中所述相同的评估策略,并在下图 5 中展示了不同方法生成的结果。
下图第一行展示了 Brain2Image 生成的结果,最后一行是研究人员提出的方法 DreamDiffusion 生成的。可以看到 DreamDiffusion 生成的图像质量明显高于 Brain2Image 生成的图像,这也验证了本文方法的有效性。
 图片
图片
消融实验
预训练的作用:为了证明大规模 EEG 数据预训练的有效性,该研究使用未经训练的编码器来训练多个模型进行验证。其中一个模型与完整模型相同,而另一个模型只有两层的 EEG 编码层,以避免数据过拟合。在训练过程中,这两个模型分别进行了有 / 无 CLIP 监督的训练,结果如表 1 中 Model 列的 1 到 4 所示。可以看到,没有经过预训练的模型准确性有所降低。
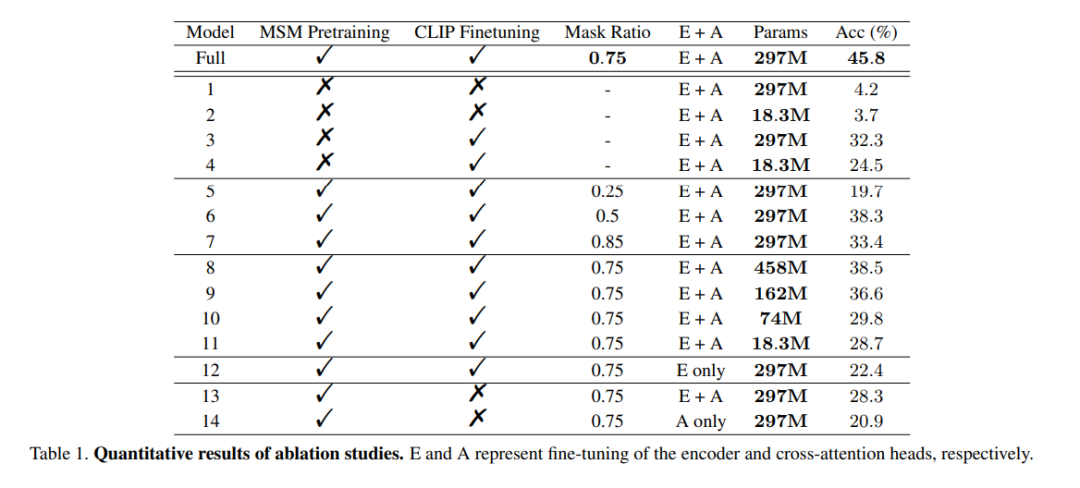
mask ratio:本文还研究了用 EEG 数据确定 MSM 预训练的最佳掩码比。如表 1 中的 Model 列的 5 到 7 所示,过高或过低的掩码比会对模型性能都会产生不利影响。当掩码比为 0.75 达到最高的整体准确率。这一发现至关重要,因为这表明,与通常使用低掩码比的自然语言处理不同,在对 EEG 进行 MSM 时,高掩码比是一个较好的选择。
CLIP 对齐:该方法的关键之一是通过 CLIP 编码器将 EEG 表征与图像对齐。该研究进行实验验证了这种方法的有效性,结果如表 1 所示。可以观察到,当没有使用 CLIP 监督时,模型的性能明显下降。实际上,如图 6 右下角所示,即使在没有预训练的情况下,使用 CLIP 对齐 EEG 特征仍然可以得到合理的结果,这凸显了 CLIP 监督在该方法中的重要性。
 图片
图片
以上就是你大脑中的画面,现在可以高清还原了的详细内容,更多请关注其它相关文章!
# ai
# stable diffusion
# 脑中
# 掩码
# 程序设计
# 所示
# 创意
# 成都seo优化工作
# 嘉兴搜索营销推广
# 成都外贸网站建设价钱
# 荥阳seo排名优化
# 童装怎么营销主题推广语
# 江苏网站建设口碑推荐
# 营销型微博手机推广
# 美剧seo
# SEO 秘籍
# 成都建设网站公司
# 并在
# 重构
# 不太
# 很好
# 万元
# 高质量
相关栏目:
【
行业新闻62819 】
【
科技资讯67470 】
相关推荐:
美图秀秀发布7款AI产品:支持用户创作、商业创作
人工智能产业协同创新中心:全产业链资源在这里汇聚
全场景智能车:智能无处不在|芯驰亮相世界人工智能大会
张朝阳与陆川谈AI:ChatGPT是鹦鹉学舌思维,不可能取代人类 | 把脉AI大模型
V社回应拒绝上架含 AI 生成内容的游戏:审核政策正在调整中
华为云天筹AI求解器荣获世界人工智能大会最高奖
Nature封面:量子计算机离实际应用还有两年
你们的开机第一屏画面要变了!安卓机器人首次3D化
华为云发布华为云盘古模型3.0和升腾AI云服务,亮点亮相2025华为开发者大会
应对算力挑战,亚马逊云科技发力AI基础设施建设
印象笔记开放旗下“印象 AI”,可一键生成思维导图、写文章等
Meta发布音频AI模型,仅需2秒片段模拟真人语音
海南科技职业大学第25届中国机器人及人工智能大赛海南赛区荣获一等奖等114项
12页线性代数笔记登GitHub热榜,还获得了Gilbert Strang大神亲笔题词
标贝科技亮相国际顶会ICASSP2025 加速布局海外AI数据市场
管提需求,大模型解决问题:图表处理神器SheetCopilot上线
美图公司:Wink国内首发AI画面拓展功能
精准度可提高 20%:英国九家银行签约使用基于 AI 的“消费者欺诈风险系统”应对*
两型无人机完成交付!国家级机动观测业务正式启动
从数据中心到发电站:人工智能对能源使用的影响
GPT-4是如何工作的?哈佛教授亲自讲授
上海发布大模型政策 打造AI“模”都
机构研选 | 虚拟电厂是电力物联网升级版 智能电网望迎来高速发展
揭秘AI数字人语录:抖音AI小和尚、老者语录能赚钱吗?
洞穴探险神器?可自主导航的单旋翼自旋无人机,效率更高!
人工智能赋能无人驾驶:商业化进程再提速
赋能金融新生态,多家银行创新应用成果亮相世界人工智能大会
研究表明 GPT-4 模型具备自我纠错能力,有望推动 AI 代码进一步商业化
微软新出热乎论文:Transformer扩展到10亿token
创新全场景清洁方案!海尔商用机器人首发上市
AI无法对传统文化符号进行解构和创新
七大主流AI企业包括OpenAI、谷歌等联合承诺:引入水印技术,并允许第三方审核AI内容
Snap宣布研发出新技术 可大幅提升AI生成图像速度
面向AI大模型,腾讯云首次完整披露自研星脉高性能计算网络
国内AI大模型“安卓时刻”到来!阿里云通义千问免费、开源、可商用
世界人工智能大会上,科大讯飞宣布与华为联手
《爱康未来之夜嘉宾官宣,携手共赴AI未来》
谷歌推出新 AI 工具 Imagen Editor,一句话对图片二次创作
谷歌借AI打破十年排序算法封印,每天被执行数万亿次,网友却说是最不切实际的研究?
业内领先 四川大学华西第四医院甲状腺乳腺外科成功进入手术机器人时代
传字节内测对话式 AI 产品,代号「Grace」;马斯克嘲讽苹果 头显;比亚迪 F 品牌定名「方程豹」
GPT-4最全攻略来袭!OpenAI官方发布,六个月攒下来的使用经验都在里面了
找对了风口想不火都难,乐天派机器人,安卓机器人的最终形态?
此「错」并非真的错:从四篇经典论文入手,理解Transformer架构图「错」在何处
如何用户外电源给无人机实现持久续航
6月14日《星空下的对话》 张朝阳陆川将畅聊人生、电影、心理学与AI
乐天派桌面机器人加入小米米家生态系统,实现与其他智能设备的互联
央广车联网亮相2025世界人工智能大会
Unity发布Sentis和Muse AI工具,助力创作游戏和3D内容
人工智能:解决劳动力短缺的关键策略
 当前位置:
当前位置:  上一篇:
上一篇: 返回列表
返回列表