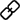400 128 6709

行业新闻
 发布时间:2024-03-18
发布时间:2024-03-18 点击次数:
点击次数: 今天我想分享一个最新的研究工作,这项研究来自康涅狄格大学,提出了一种将时间序列数据与自然语言处理(nlp)大模型在隐空间上对齐的方法,以提高时间序列预测的效果。这一方法的关键在于利用隐空间提示(prompt)来增强时间序列预测的准确性。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

论文标题:S2IP-LLM: Semantic Space Informed Prompt Learning with LLM for Time Series Forecasting
下载地址:https://www.php.cn/link/3695d85c350d924e662ea2cd3b760d40
大模型在时间序列上的应用越来越多,主要分为两类:第一类使用各类时间序列数据训练一个时间序列领域自己的大模型;第二类直接使用NLP领域训练好的文本大模型应用到时间序列中。由于时间序列不同于图像、文本,不同数据集的输入格式不同、分布不同,且存在distribution shift等问题,导致使用所有时间序列数据训练统一的模型比较困难。因此,越来越多的工作开始尝试如何直接使用NLP大模型解决时间序列相关问题。
本文还关注第二种解决时间序列问题的方法,即利用NLP大模型。目前的做法通常使用时间序列的描述作为提示,但并非所有时间序列数据集都包含这种信息。此外,基于patch的时间序列数据处理方法也无法完全保留时间序列数据的所有信息。
基于上述 问题,这篇文章提出了一种新的建模方法,核心建模思路,一方面将时间序列通过tokenize处理后映射成embedding,另一方面将这些时间序列空间的表征对齐到大模型中的word embedding上。通过这种方式,让时间序列的预测过程中,可以找到对齐的word embedding相关的信息作为prompt,提升预测效果。
问题,这篇文章提出了一种新的建模方法,核心建模思路,一方面将时间序列通过tokenize处理后映射成embedding,另一方面将这些时间序列空间的表征对齐到大模型中的word embedding上。通过这种方式,让时间序列的预测过程中,可以找到对齐的word embedding相关的信息作为prompt,提升预测效果。
 图片
图片
下面从数据处理、隐空间对齐、模型细节等3个方面介绍一下这篇工作的实现方法。
 Machine Translation
Machine Translation
聚合多个来源的AI翻译
 49
查看详情
49
查看详情

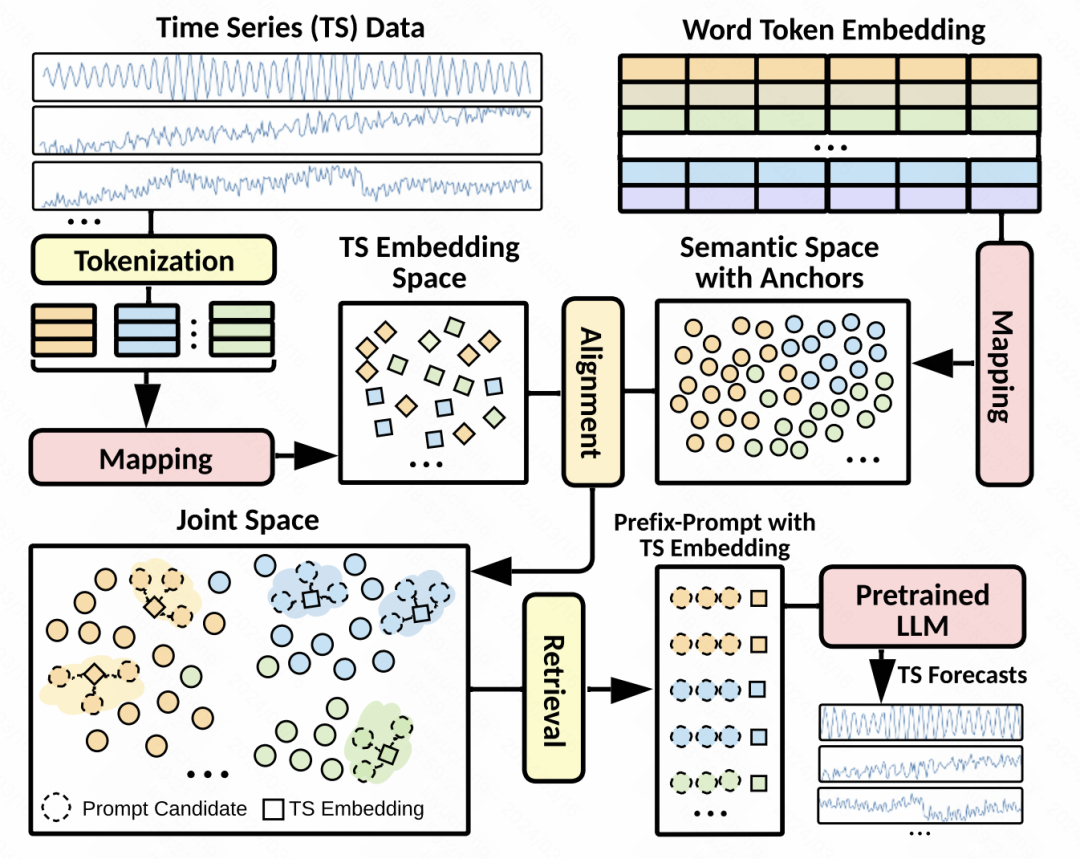
数据处理:由于时间序列的distribution shift等问题,本文对输入序列做了一步趋势项季节项分解。每个分解后的时间序列,都单独做标准化,然后分割成有重叠的patch。每一组patch对应趋势项patch、季节项patch、残差patch,将这3组patch拼接到一起,输入到MLP中,得到每组patch的基础embedding表征。
隐空间对齐:这是本文中最核心的一步。Prompt的设计对大模型的效果影响很大,而时间序列的prompt又难以设计。因此本文提出,将时间序列的patch表征和大模型的word embedding在隐空间对齐,然后检索出topK的word embedding,作为隐式的prompt。具体做法为,使用上一步生成的patch embedding,和语言模型中的word embedding计算余弦相似度,选择topK的word embedding,再将这些word embedding作为prompt,拼接到时间序列patch embedding的前方。由于大模型word embedding大多,为了减少计算量,先对word embedding做了一步映射,映射到数量很少的聚类中心上。
模型细节:在模型细节上,使用GPT2作为语言模型部分,除了position embedding和layer normalization部分的参数外,其余的都冻结住。优化目标除了MSE外,还引入patch embedding和检索出的topK cluster embedding的相似度作为约束,要求二者之间的距离越小越好。最终的预测结果,也是
 图片
图片
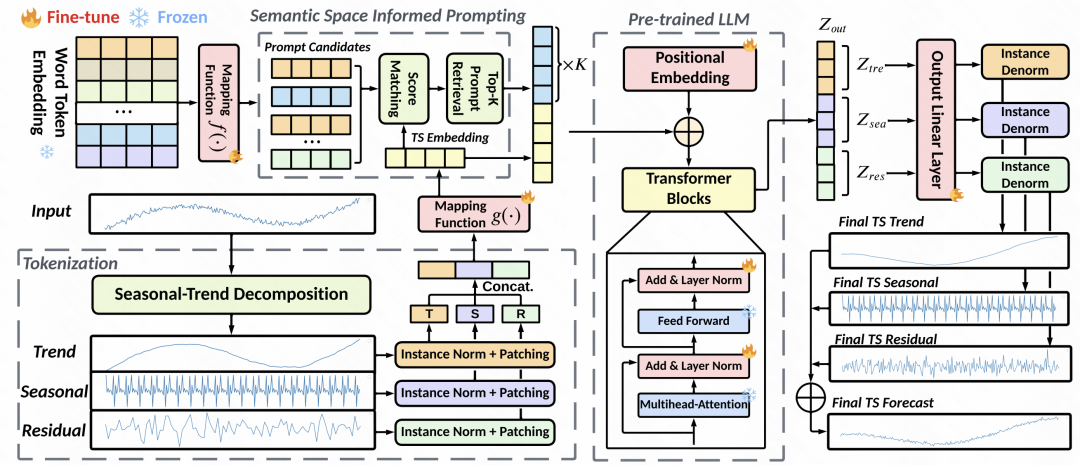
文中对比了和一些时间序列大模型、iTransformer、PatchTST等SOTA模型的效果,在大部分数据集的不同时间窗口的预测中都取得了比较好的效果提升。
 图片
图片
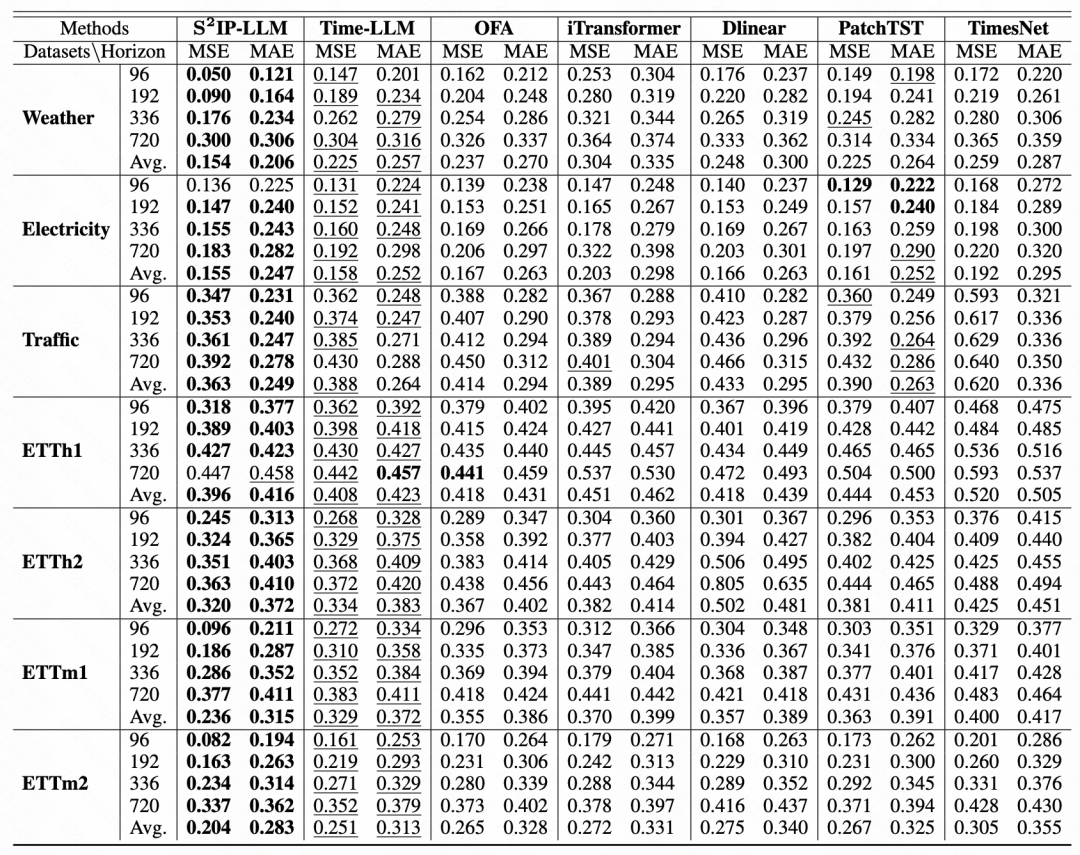
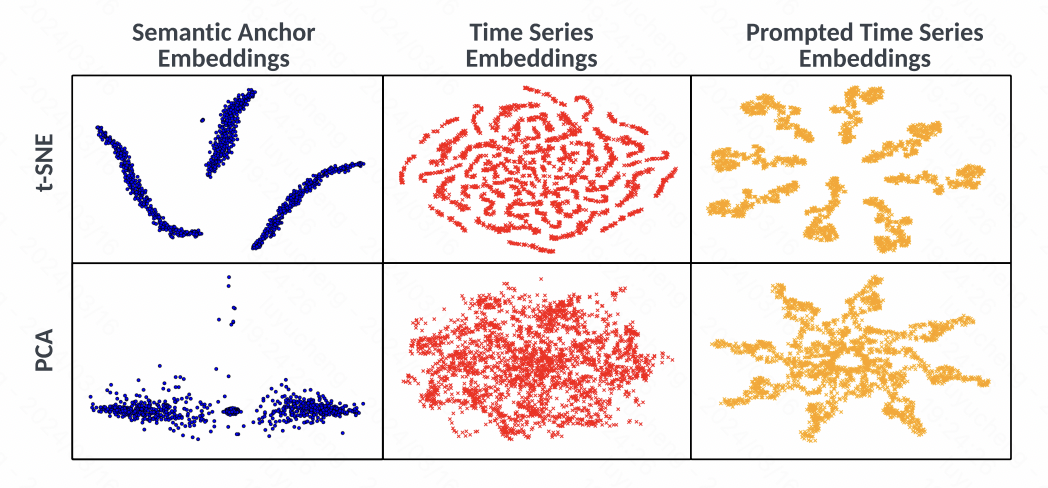
同时,文中也通过t-SNE可视化分析了embedding,从图中可以看出,时间序列的embedding在对齐之前并没有明显的类簇现象,而通过prompt生成的embedding有明显的类簇变化,说明本文提出的方法有效的利用文本和时间序列的空间对齐,以及相应的prompt,提升时间序列表征的质量。
 图片
图片
以上就是时间序列预测+NLP大模型新作:为时序预测自动生成隐式Prompt的详细内容,更多请关注其它相关文章!
# 中国
# 外语外贸网站建设
# 家居网站推广怎么做的好
# 纸业网站推广推荐
# 一个营销号推广多少钱
# 自学seo虾哥网络
# 建材网站推广哪里专业
# 营销号的推广方案设计
# 移动端关键词排名代理
# 利川推广网站
# 海南的论坛网站建设
# 开源
# 模型
# 上海
# 康涅狄格
# 提出了
# 丰田
# 中国科学院
# 数据处理
# 隐式
# 自动生成
# follow
# prompt
# 时间序列
相关栏目:
【
行业新闻62819 】
【
科技资讯67470 】
相关推荐:
华为大模型登Nature正刊!审稿人:让人们重新审视预报模型的未来
Valve Index VR 头显销量下滑,上市四年的长青树渐失光彩
定义人工智能的十个关键术语
烟台大学学生首次在全国大学生无人机航拍竞赛中获奖
人工智能如何与智能家居集成
英特尔张宇:边缘计算在整个AI生态系统中扮演重要角色
七大主流AI企业包括OpenAI、谷歌等联合承诺:引入水印技术,并允许第三方审核AI内容
微软新出热乎论文:Transformer扩展到10亿token
自己动手使用AI技术实现数字内容生产
人形机器人概念大热!这些产业链标的或受提振
美妆行业在AI时代蓬勃发展
学而思推出AI第一课:基于自研大模型的AIGC课程
生活垃圾智能分类机器人社区展“才能”,征求居民意见
创作音乐/音频的Meta开源AI工具AudioCraft,让用户通过文本提示实现
郭帆:AI发展日新月异,或是弯道超车好莱坞的最好机会
人工智能创作的“婴儿版超级英雄”,你觉得哪个最可爱
软通动力天枢元宇宙研究院签约落户江宁高新区
微软 Copilot 团队主管呼吁用户与 AI 交流时应使用恰当的礼貌用语
美图第二届影像节发布七款AI影像创作工具
联通发布鸿湖图文AI大模型1.0,可实现以文生图
鉴智机器人发布基于地平线征程5的标准视觉感知产品
VMS的应用:提升多品牌设备管理效能
「模仿学习」只会套话?解释微调+130亿参数Orca:推理能力打平ChatGPT
OpenAI大神Karpathy最新分享:为什么OpenAI内部对AI Agents最感兴趣
OpenAI限制网络爬虫访问以保护数据免被用于AI模型训练
美踏控股推出创新人工智能大数据模型“心乐舞河”:虚拟人音舞社交的新体验
如何用AI开创智慧能源新时代?固德威正让能源“通人性”!
阿里云全面支持Llama2训练部署,助力企业快速构建自有大型模型
从数据中心到发电站:人工智能对能源使用的影响
独家视角:首次展示有人与无人协同打击的7000米高空察打一体无人机
“图壤·阅读元宇宙”亮相北京国际图书博览会
大语言模型的视觉天赋:GPT也能通过上下文学习解决视觉任务
阿里达摩院向公众免费开放100项AI专利许可
微软宣布为 Azure AI 添加男性声线,增强文本转语音功能
苹果AIGC专利:可通过语音指令生成AR/VR虚拟场景
美图秀秀发布7款AI产品:支持用户创作、商业创作
腾讯企点客服接待与营销分析能力升级!企业操作更高效、人机交互更智能
眼球反射解锁3D世界,黑镜成真!马里兰华人新作炸翻科幻迷
张朝阳与陆川谈AI:ChatGPT是鹦鹉学舌思维,不可能取代人类 | 把脉AI大模型
联想浏览器引入小乐 AI 助手,成功接入百度文心一言大模型,经过实测证实
科技赋能司法执行 阿里资产免费为全国法院升级VR新服务
360发布AI数字人广场,可同孙悟空、爱因斯坦等古今中外角色对话
专家解读国家网信办深度合成服务算法备案信息公告:不等于百度、阿里、腾讯等生成式AI产品获批
谷歌推出新 AI 工具 Imagen Editor,一句话对图片二次创作
江永:精准施训提升通信无人机应急救援能力
机构:边缘AI或是当前预期差最大的AI方向
复盘MWC上海:AI大模型时代到来 通信网络将会怎样改变?
AI在教育中的角色:AI如何改变我们的学习方式
消息称 Meta Quest 将推 VR 游戏订阅:每月 7.99 美元,任选两款
高质量数据推动AI场景化应用快速发展及落地
 当前位置:
当前位置:  上一篇:
上一篇: 返回列表
返回列表