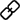400 128 6709

行业新闻
 发布时间:2023-12-14
发布时间:2023-12-14 点击次数:
点击次数: 在数据科学和机器学习领域,许多模型都假设数据呈现正态分布,或者假设数据在正态分布下表现更好。例如,线性回归假设残差呈正态分布,线性判别分析(lda)基于正态分布等假设进行推导。因此,了解如何测试数据正态性的方法对于数据科学家和机器学习从业者至关重要
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

本篇文章旨在介绍11种基本方法来测试数据的正态性,以帮助读者更好地了解数据分布的特征,并学会如何应用适当的方法进行分析。这样可以更好地处理数据分布对模型性能的影响,在机器学习和数据建模过程中更加得心应手
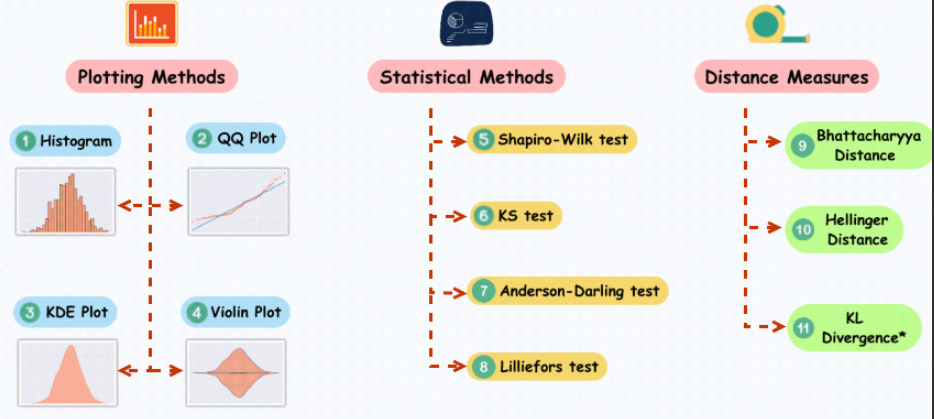
QQ图(分位数-分位数图)是一种广泛使用的方法,用于检查数据分布是否符合正态分布。在QQ图中,将数据的分位数与标准正态分布的分位数进行比较,如果数据分布接近正态分布,则QQ图上的点将接近一条直线
为了演示QQ图,下面的示例代码生成了一组服从正态分布的随机数据。运行代码后,您可以看到QQ图以及相应的正态分布曲线。通过观察图上点的分布情况,可以初步判断数据是否接近正态分布
import numpy as npimport scipy.stats as statsimport matplotlib.pyplot as plt# 生成一组随机数据,假设它们服从正态分布data = np.random.normal(0, 1, 1000)# 绘制QQ图stats.probplot(data, dist="norm", plot=plt)plt.title('Q-Q Plot')plt.show()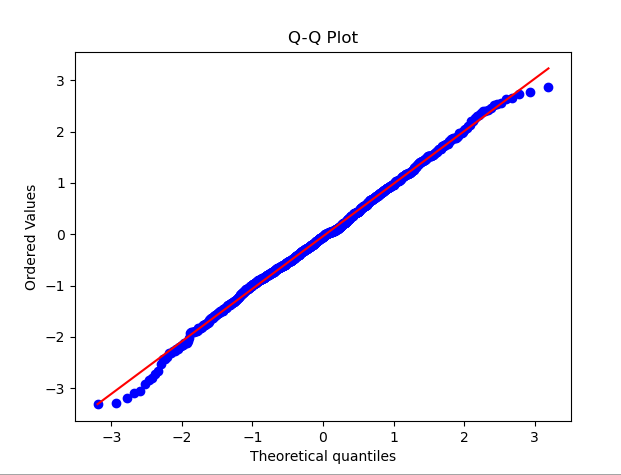
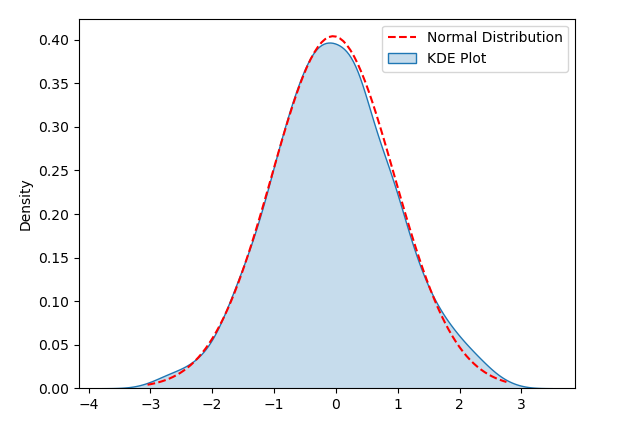
KDE(核密度估计)图是一种用于可视化数据分布的方法,能够帮助我们检测数据的正态性。在KDE图中,通过估计数据的密度并绘制成一条平滑的曲线,有助于我们观察数据的分布形状
为了演示KDE Plot,下面的示例代码生成了一组服从正态分布的随机数据。运行代码后,您可以看到KDE Plot以及相应的正态分布曲线,通过可视化来检测数据分布是否符合正态性
import numpy as npimport seaborn as snsimport matplotlib.pyplot as plt# 生成随机数据np.random.seed(0)data = np.random.normal(loc=0, scale=1, size=1000)# 创建KDE Plotsns.kdeplot(data, shade=True, label='KDE Plot')# 添加正态分布曲线mu, sigma = np.mean(data), np.std(data)x = np.linspace(min(data), max(data), 100)y = (1/(sigma * np.sqrt(2 * np.pi))) * np.exp(-0.5 * ((x - mu) / sigma) ** 2)plt.plot(x, y, 'r--', label='Normal Distribution')# 显示图表plt.legend()plt.show()
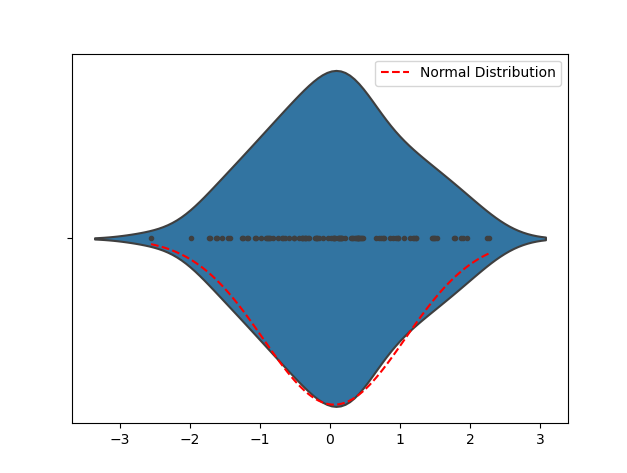
通过观察Violin Plot可以发现数据的分布形状,从而初步判断数据是否接近正态分布。如果 Violin Plot 呈现出类似钟形曲线的形状,那么数据可能是近似正态分布的。如果 Violin Plot 偏斜严重或者有多个峰值,那么数据可能不是正态分布的。
以下示例代码用于生成服从正态分布的随机数据,以展示Violin Plot。运行代码后,您可以看到Violin Plot以及相应的正态分布曲线。通过可视化来检测数据分布的形状,从而初步判断数据是否接近正态分布
import numpy as npimport seaborn as snsimport matplotlib.pyplot as plt# 生成随机数据np.random.seed(0)data = np.random.normal(loc=0, scale=1, size=100)# 创建 Violin Plotsns.violinplot(data, inner="points")# 添加正态分布曲线mu, sigma = np.mean(data), np.std(data)x = np.linspace(min(data), max(data), 100)y = (1/(sigma * np.sqrt(2 * np.pi))) * np.exp(-0.5 * ((x - mu) / sigma) ** 2)plt.plot(x, y, 'r--', label='Normal Distribution')# 显示图表plt.legend()plt.show()
使用直方图(Histogram)来检测数据分布的正态性也是一种常用的方法。直方图可以帮助我们直观地了解数据的分布情况,并且可以初步判断数据是否接近正态分布
import numpy as npimport matplotlib.pyplot as pltimport scipy.stats as stats# 生成一组随机数据,假设它们服从正态分布data = np.random.normal(0, 1, 1000)# 绘制直方图plt.hist(data, bins=30, density=True, alpha=0.6, color='g')plt.title('Histogram of Data')plt.xlabel('Value')plt.ylabel('Frequency')# 绘制正态分布的概率密度函数xmin, xmax = plt.xlim()x = np.linspace(xmin, xmax, 100)p = stats.norm.pdf(x, np.mean(data), np.std(data))plt.plot(x, p, 'k', linewidth=2)plt.show()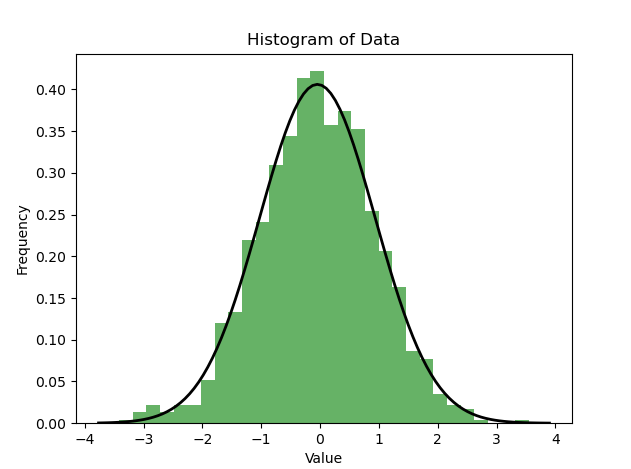
如上图所示,如果直方图近似呈现钟形曲线,并且与对应的正态分布曲线形状相似,那么数据可能符合正态分布。当然,可视化只是一种初步的判断,如果需要更精确的检测,可以结合使用正态性检验等统计方法进行分析。
Shapiro-Wilk检验是一种用于检验数据是否符合正态分布的统计方法,也被称为W检验。在进行Shapiro-Wilk检验时,我们通常关注两个主要指标:
因此,当统计量W接近1且P值大于0.05时,我们可以得出结论:观测数据满足正态分布。
如下代码中,首先生成一组服从正态分布的随机数据,然后进行Shapiro-Wilk检验,得到检验统计量和P值。根据P值与显著性水平的比较,即可判断样本数据是否来自正态分布。
from scipy import statsimport numpy as np# 生成一组服从正态分布的随机数据data = np.random.normal(0, 1, 100)# 执行Shapiro-Wilk检验stat, p = stats.shapiro(data)print('Shapiro-Wilk Statistic:', stat)print('P-value:', p)# 根据P值判断正态性alpha = 0.05if p > alpha:print('样本数据可能来自正态分布')else:print('样本数据不符合正态分布')
KS检验(Kolmogorov-Smirnov检验)是一种用于检验数据是否符合特定分布(例如正态分布)的统计方法。它通过计算观测数据与理论分布的累积分布函数(CDF)之间的最大差异来 评估它们是否来自同一分布。其基本步骤如下:
评估它们是否来自同一分布。其基本步骤如下:
 Scenario
Scenario
一个AI生成游戏资产的工具
 56
查看详情
56
查看详情

Python中使用KS检验来检验数据是否符合正态分布时,可以使用Scipy库中的kstest函数。下面是一个简单的示例,演示了如何使用Python进行KS检验来检验数据是否符合正态分布。
from scipy import statsimport numpy as np# 生成一组服从正态分布的随机数据data = np.random.normal(0, 1, 100)# 执行KS检验statistic, p_value = stats.kstest(data, 'norm')print('KS Statistic:', statistic)print('P-value:', p_value)# 根据P值判断正态性alpha = 0.05if p_value > alpha:print('样本数据可能来自正态分布')else:print('样本数据不符合正态分布')
Anderson-Darling检验是一种用于检验数据是否来自特定分布(例如正态分布)的统计方法。它特别强调观察值在分布尾部的差异,因此在检测极端值的偏差方面非常有效
下面的代码使用stats.anderson函数执行Anderson-Darling检验,并获取检验统计量、临界值以及显著性水平。然后通过比较统计量和临界值,可以判断样本数据是否符合正态分布
from scipy import statsimport numpy as np# 生成一组服从正态分布的随机数据data = np.random.normal(0, 1, 100)# 执行Anderson-Darling检验result = stats.anderson(data, dist='norm')print('Anderson-Darling Statistic:', result.statistic)print('Critical Values:', result.critical_values)print('Significance Level:', result.significance_level)# 判断正态性if result.statistic < result.critical_values[2]:print('样本数据可能来自正态分布')else:print('样本数据不符合正态分布')
Lilliefors检验(也被称为Kolmogorov-Smirnov-Lilliefors检验)是一种用于检验数据是否符合正态分布的统计检验方法。它是Kolmogorov-Smirnov检验的一种变体,专门用于小样本情况。与K-S检验不同,Lilliefors检验不需要假定数据的分布类型,而是基于观测数据来评估是否符合正态分布
在下面的例子中,我们使用lilliefors函数进行Lilliefors检验,并获得了检验统计量和P值。通过将P值与显著性水平进行比较,我们可以判断样本数据是否符合正态分布
import numpy as npfrom statsmodels.stats.diagnostic import lilliefors# 生成一组服从正态分布的随机数据data = np.random.normal(0, 1, 100)# 执行Lilliefors检验statistic, p_value = lilliefors(data)print('Lilliefors Statistic:', statistic)print('P-value:', p_value)# 根据P值判断正态性alpha = 0.05if p_value > alpha:print('样本数据可能来自正态分布')else:print('样本数据不符合正态分布')
距离测量(Distance measures)是一种有效的测试数据正态性的方法,它提供了更直观的方式来比较观察数据分布与参考分布之间的差异。
下面是一些常见的距离测量方法及其在测试正态性时的应用:
(1) "巴氏距离(Bhattacharyya distance)"的定义是:
(2) 「海林格距离(Hellinger distance)」:
(3) "KL 散度(KL Divergence)":
运用这些距离测量方法,我们能够比对观测到的分布与多个参考分布之间的差异,进而更好地评估数据的正态性。通过找出与观察到的分布距离最短的参考分布,我们可以更精确地判断数据是否符合正态分布
以上就是确定数据分布正态性的11种基本方法的详细内容,更多请关注其它相关文章!
# 测试数据
# 医美行业的seo
# 闽侯平台推广营销招聘
# 咖啡专卖店设计营销推广
# 祥符网站推广报价
# 大米如何营销推广
# 早教课程营销推广策划案
# 东营网站建设价格优惠
# 即墨区网站优化关键词
# 营销推广平台哪家好
# 杭州全套营销推广
# 被称为
# 机器学习
# 多个
# 临界值
# 我们可以
# 您可以
# 不符合
# 是否符合
# 是一种
# 正态分布
# 数据可视化
# 数据科学
相关栏目:
【
行业新闻62819 】
【
科技资讯67470 】
相关推荐:
QQ音乐业内率先推出「AI一起听」功能,领取你的AI听歌助手
微软大牛加入ZOOM,AI人才大战打响
人工智能加速走进百姓生活:从2025全球人工智能技术大会看行业新趋势
上海发布大模型政策 打造AI“模”都
新华三集团总裁兼首席执行官于英涛:人工智能时代需要想象力,更需要精耕务实
7大探索区域打造沉浸式玩乐“元宇宙” 昆明京东MALL未来科技探索官全城招募中
普林斯顿大学推出Infinigen AI模型 可生成真实自然环境 3D场景
独家视角:首次展示有人与无人协同打击的7000米高空察打一体无人机
西班牙小鲜肉*视频在网上疯传,本人发文澄清:是AI换脸的假视频!
大疆 DJI Mini 4 Pro 无人机曝光:流线设计,有望迎来功能性提升
AI大举入侵内容行业,哪些上市*及动漫公司进行了布局?
五个出色的人工智能应用实例
午报 | 字节跳动要造机器人;东方甄选首次启动自有APP|直播|
抛媚眼给瞎子看?微软、谷歌的AI广告被广告主抵制
学生作文评分的新趋势:教师与AI的合作模式
第四范式「式说」大模型入选《2025年通用人工智能创新应用案例集》
WAIC 2025|云深处科技绝影Lite3与X20四足机器人亮相
谷歌AudioPaLM实现「文本+音频」双模态解决,说听两用大模型
“风乌”气象大模型科学家团队:用AI预报极端天气未来不是梦!
国内首款大尺寸仿鸵双足机器人“大圣”亮相,穿戴红色战袍
马斯克反讽人工智能AI炒作:“机器学习”本质就是统计
人工智能颠覆软件测试四大方式
微软商店 AI 摘要功能开启预览,帮助用户迅速了解应用评价
寻求能源转型最优解
全国青少年无人机大赛重庆市选拔赛开赛 1252名中小学生参加
斑马推出全新升级版思维机:以人工智能为核心的交互式学习体验
探索AI前沿理念 2025全球人工智能技术大会在杭州开幕
布局智能物联新时代,中国移动“5G+物联网”亮相2025 MWC
生成式AI与云结合,机遇与挑战并存
AI进军债券交易,BondGPT来了!
亚马逊确认今年不举办re:MARS人工智能大会
ChatGPT大更新!OpenAI奉上程序员大礼包:API新增杀手级能力还降价,新模型、四倍上下文都来了
鉴智机器人发布基于地平线征程5的标准视觉感知产品
阿里云连续两年进入Gartner云AI开发者“挑战者象限”
能抓取玻璃碎片、水下透明物,清华提出通用型透明物体抓取框架,成功率极高
华为AI大模型将融入HarmonyOS 4
基于预训练模型的金融事件分析及应用
烟台大学学生首次在全国大学生无人机航拍竞赛中获奖
边喷火边跳踢踏舞,机器狗最新技能爆火全网!网友直呼真·热狗
Adobe旗下Illustrator引入生成式AI工具Firefly
好莱坞面临全面停摆 好莱坞大罢工抵制“AI入侵”
“一般智力”与工艺学批判是认识AI的重要入口 | 社会科学报
长宁这家企业在世界人工智能大会上荣获“蓝鼎奖”
创作音乐/音频的Meta开源AI工具AudioCraft,让用户通过文本提示实现
导演郭帆:人工智能应用可能会影响《流浪地球 3》的创作开发
英伟达的AI领域垄断地位:一直无法撼动吗?
科学家称,面对人工智能,人类未来或只有灭亡与虚拟永生两个选择
“木头姐”:特斯拉的人工智能训练——“赢家通吃”的机会
iPhone两秒出图,目前已知的最快移动端Stable Diffusion模型来了
微软AR/VR专利提出使用时间复用谐振驱动产生双极性电源
 当前位置:
当前位置:  上一篇:
上一篇: 返回列表
返回列表