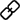400 128 6709

行业新闻
 发布时间:2025-08-01
发布时间:2025-08-01 点击次数:
点击次数: 本文分析了Softmax与线性注意力的性能差距,指出核心在于单射性质和局部建模能力。线性注意力因非单射导致语义混淆,且局部建模不足;Softmax注意力则具备单射性和强局部建模能力。据此提出InLine注意力,通过改进归一化赋予单射性,实验证明其在保持线性复杂度的同时,性能可优于Softmax注意力。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

Softmax注意力被广泛应用于现代视觉Transformer设计中,可以有效地捕获远程视觉信息;然而,在处理高分辨率输入时,它会产生过高的计算成本。相比之下,线性注意力自然具有线性复杂性,并且具有扩展到更高分辨率图像的巨大潜力。然而,线性注意力的不理想性能极大地限制了它在各种场景中的实际应用。在本文中,我们向前迈进了一步,用新颖的理论分析来缩小线性和Softmax注意力之间的差距,揭示了性能偏差背后的核心因素。具体来说,我们提出了两个关键的观点来理解和减轻线性注意力的局限性:单射性质和局部建模能力。首先,我们证明了线性注意力不是单射的,这很容易给不同的查询向量分配相同的注意力权重,从而增加了严重的语义混淆,因为不同的查询对应相同的输出。其次,我们证实了有效的局部建模对于Softmax注意力的成功至关重要,而线性注意力的不足。上述两个基本差异显著地促成了这两种注意范式之间的差异,这在本文中得到了大量的实证验证。此外,更多的实验结果表明,只要赋予线性注意力这两个属性,在保持较低的计算复杂度的同时,可以在各种任务中优于Softmax注意力。
由于线性计算复杂度较低,线性注意力被视为解决高分辨率场景中softmax注意力计算挑战的有前途的解决方案。然而,先前的研究表明,线性注意力的表示能力远低于softmax注意力,使其在实际应用中不可行。在本节中,作者从两个视角深入分析了线性注意力与softmax注意力之间的差距:单射和局部建模能力
在本文中,作者发现注意力函数的单射性质对模型性能有显著影响,这可能很大程度上解释了线性注意力和 Softmax 注意力之间的差距。具体来说,在温和的假设下,作者证明 Softmax 注意力函数 SK 是单射的,而线性注意力函数 LK不是。因此,对于两个不同的 Query p 和 q (p=q) ,Softmax 注意力应该产生不同的注意力分布 SK(p)=SK(q) ,而线性注意力可能会产生相同值 LK(p)=LK(q) 。由于典型的不同 Query p=q 代表不同的语义,线性注意力的非单射性质实际上会导致语义混淆,即 LK(p)=LK(q) 且 OpL=LK(p)⊤V=LK(q)⊤V=OqL ,使模型无法区分某些语义。
如下图所示,如图(a)所示,有四个共线且长度不同的向量。借助单射性质,Softmax注意力确保每个 Query 获得不同的注意力分数,从而生成更聚焦的注意力分布,特别是对于较长的 Query 。然而,当使用核函数 ϕ(⋅)=ReLU(⋅),时,线性注意力无法区分强度不同但语义相同的 Query ,即具有不同长度的不同强度的共线 Query ,导致这四个 Query 得到完全相同的关注度分数。因此,线性注意力无法为更强的语义生成更聚焦的关注度得分。当使用具有更强非线性的核函数 ϕ(⋅)=ReLU(A⋅+b) 时,线性注意力会遇到更为显著的混淆问题。例如,在图(b)中,使用核函数 ϕ(⋅)=ReLU(A⋅+b) 时,线性注意力会给方向和长度不同的四个 Query 分配完全相同的关注度分数。这种严重的语义混淆可以直接损害模型的性能。
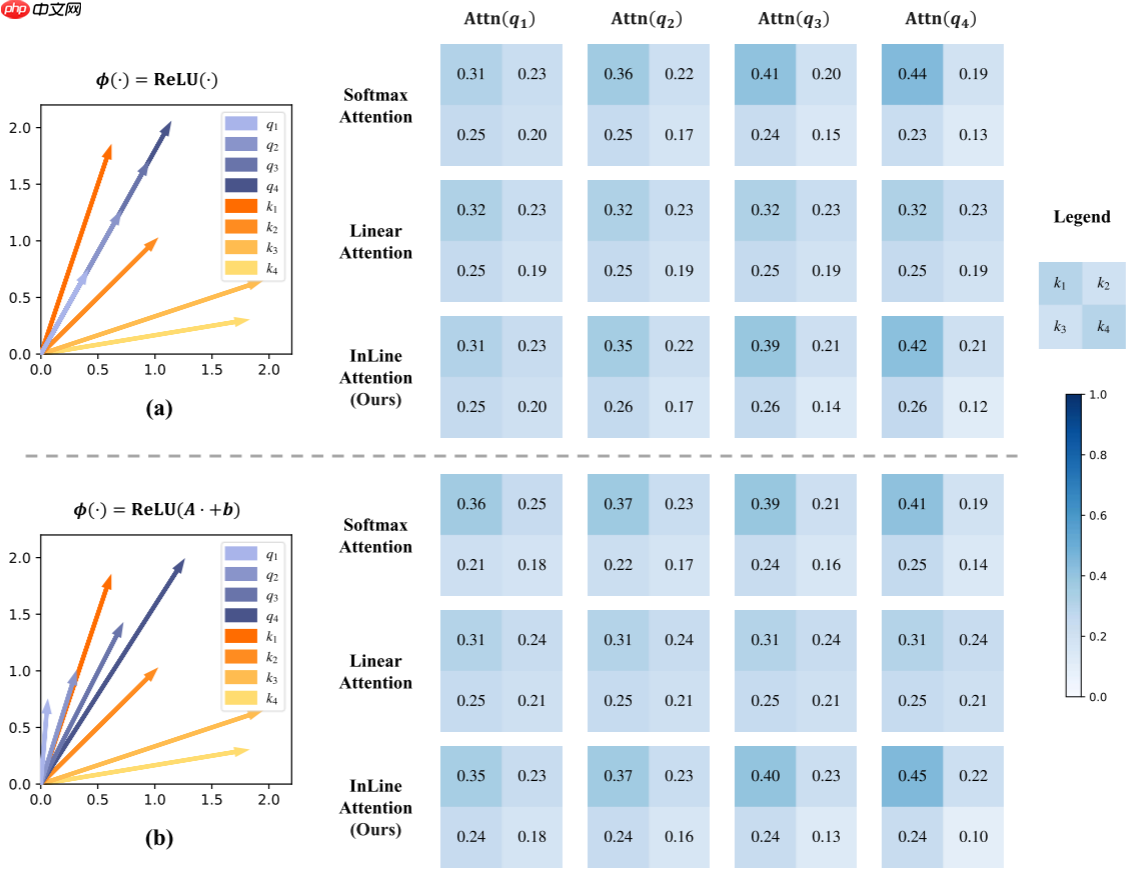
进一步在真实场景中量化混淆问题,发现在ImageNet验证集中,Softmax注意力几乎没有出现混淆情况,而线性注意力出现了超过 25 次的混淆情况 。
 Openflow
Openflow
一键极速绘图,赋能行业工作流
 88
查看详情
88
查看详情

为此,本文提出了一种简单且有效的解决方案,使得线性注意力成为单射函数。在线性注意力中由于忽略了除法中的 α ,对于 ∀α=0 ,αϕ(p) 会获得相同的分数,从而导致非一一对应性。因此,作者简单地将线性注意力的归一化从除法改为减法,提出了单射线性注意力InLine,如下所示:
InLK(Qi)=[ϕ(Qi)⊤ϕ(K1),⋯,ϕ(Qi)⊤ϕ(KN)]⊤−N1s=1∑Nϕ(Qi)⊤ϕ(Ks)+N1
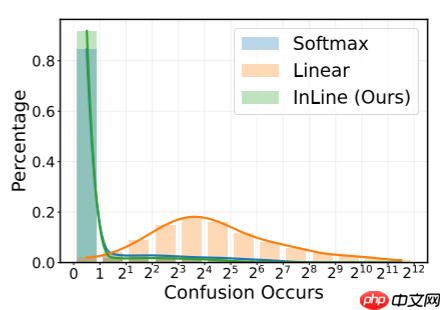
注意力机制以其大的感受野和出色的长程建模能力而著称。然而,本文发现有效的局部建模对于注意力的有效性至关重要。如下图所示,使用DeiT-T计算每个Query分配给局部3×3邻域的注意力值之和。每个DeiT-T注意力层包含总共14×14+1=197个Token,如果注意力分数随机分配,则每个 Query 的3×3邻域的期望注意力值为9/197。结果显示,所有三种注意力机制都倾向于更多关注每个Query的邻域,揭示了局部偏见,尤其是在浅层。值得注意的是,Softmax注意力分配了大量的注意力给局部窗口,表明其局部建模能力比两种其他注意力机制更强。图4提供了相应的可视化结果以进一步确认这一发现。作者认为,Softmax注意力表现更优的原因可能是它具有稳健的局部先验和强大的局部建模能力。为了验证这一假设,作者采用注意力 Mask 去除不同位置的Token,并评估它们对模型性能的影响。结果如下表所示。两个关键观察结果是:


%matplotlib inlineimport paddleimport numpy as npimport matplotlib.pyplot as pltfrom paddle.vision.datasets import Cifar10from paddle.vision.transforms import Transposefrom paddle.io import Dataset, DataLoaderfrom paddle import nnimport paddle.nn.functional as Fimport paddle.vision.transforms as transformsimport osimport matplotlib.pyplot as pltfrom matplotlib.pyplot import figurefrom models import *
train_tfm = transforms.Compose([
transforms.RandomResizedCrop(224, scale=(0.6, 1.0)),
transforms.ColorJitter(brightness=0.2,contrast=0.2, saturation=0.2),
transforms.RandomHorizontalFlip(0.5),
transforms.RandomRotation(20),
transforms.ToTensor(),
transforms.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)),
])
test_tfm = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)),
])
In [3]
paddle.vision.set_image_backend('cv2')# 使用Cifar10数据集train_dataset = Cifar10(data_file='data/data152754/cifar-10-python.tar.gz', mode='train', transform = train_tfm, )
val_dataset = Cifar10(data_file='data/data152754/cifar-10-python.tar.gz', mode='test',transform = test_tfm)print("train_dataset: %d" % len(train_dataset))print("val_dataset: %d" % len(val_dataset))
train_dataset: 50000 val_dataset: 10000In [4]
batch_size=256In [5]
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, drop_last=True, num_workers=4) val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False, drop_last=False, num_workers=4)
class LabelSmoothingCrossEntropy(nn.Layer):
def __init__(self, smoothing=0.1):
super().__init__()
self.smoothing = smoothing def forward(self, pred, target):
confidence = 1. - self.smoothing
log_probs = F.log_softmax(pred, axis=-1)
idx = paddle.stack([paddle.arange(log_probs.shape[0]), target], axis=1)
nll_loss = paddle.gather_nd(-log_probs, index=idx)
smooth_loss = paddle.mean(-log_probs, axis=-1)
loss = confidence * nll_loss + self.smoothing * smooth_loss return loss.mean()
model = inline_deit_tiny(num_classes=10) paddle.summary(model, (1, 3, 224, 224))

learning_rate = 0.0003n_epochs = 100paddle.seed(42) np.random.seed(42)In [ ]
work_path = 'work/model'# InLine Attnmodel = inline_deit_tiny(num_classes=10)
criterion = LabelSmoothingCrossEntropy()
scheduler = paddle.optimizer.lr.CosineAnnealingDecay(learning_rate=learning_rate, T_max=50000 // batch_size * n_epochs, verbose=False)
optimizer = paddle.optimizer.Adam(parameters=model.parameters(), learning_rate=scheduler, weight_decay=1e-5)
gate = 0.0threshold = 0.0best_acc = 0.0val_acc = 0.0loss_record = {'train': {'loss': [], 'iter': []}, 'val': {'loss': [], 'iter': []}} # for recording lossacc_record = {'train': {'acc': [], 'iter': []}, 'val': {'acc': [], 'iter': []}} # for recording accuracyloss_iter = 0acc_iter = 0for epoch in range(n_epochs): # ---------- Training ----------
model.train()
train_num = 0.0
train_loss = 0.0
val_num = 0.0
val_loss = 0.0
accuracy_manager = paddle.metric.Accuracy()
val_accuracy_manager = paddle.metric.Accuracy() print("#===epoch: {}, lr={:.10f}===#".format(epoch, optimizer.get_lr())) for batch_id, data in enumerate(train_loader):
x_data, y_data = data
labels = paddle.unsqueeze(y_data, axis=1)
logits = model(x_data)
loss = criterion(logits, y_data)
acc = accuracy_manager.compute(logits, labels)
accuracy_manager.update(acc) if batch_id % 10 == 0:
loss_record['train']['loss'].append(loss.numpy())
loss_record['train']['iter'].append(loss_iter)
loss_iter += 1
loss.backward()
optimizer.step()
scheduler.step()
optimizer.clear_grad()
train_loss += loss
train_num += len(y_data)
total_train_loss = (train_loss / train_num) * batch_size
train_acc = accuracy_manager.accumulate()
acc_record['train']['acc'].append(train_acc)
acc_record['train']['iter'].append(acc_iter)
acc_iter += 1
# Print the information.
print("#===epoch: {}, train loss is: {}, train acc is: {:2.2f}%===#".format(epoch, total_train_loss.numpy(), train_acc*100)) # ---------- Validation ----------
model.eval() for batch_id, data in enumerate(val_loader):
x_data, y_data = data
labels = paddle.unsqueeze(y_data, axis=1) with paddle.no_grad():
logits = model(x_data)
loss = criterion(logits, y_data)
acc = val_accuracy_manager.compute(logits, labels)
val_accuracy_manager.update(acc)
val_loss += loss
val_num += len(y_data)
total_val_loss = (val_loss / val_num) * batch_size
loss_record['val']['loss'].append(total_val_loss.numpy())
loss_record['val']['iter'].append(loss_iter)
val_acc = val_accuracy_manager.accumulate()
acc_record['val']['acc'].append(val_acc)
acc_record['val']['iter'].append(acc_iter) print("#===epoch: {}, val loss is: {}, val acc is: {:2.2f}%===#".format(epoch, total_val_loss.numpy(), val_acc*100)) # ===================s*e====================
if val_acc > best_acc:
best_acc = val_acc
paddle.s*e(model.state_dict(), os.path.join(work_path, 'best_model.pdparams'))
paddle.s*e(optimizer.state_dict(), os.path.join(work_path, 'best_optimizer.pdopt'))print(best_acc)
paddle.s*e(model.state_dict(), os.path.join(work_path, 'final_model.pdparams'))
paddle.s*e(optimizer.state_dict(), os.path.join(work_path, 'final_optimizer.pdopt'))
def plot_learning_curve(record, title='loss', ylabel='CE Loss'):
''' Plot learning curve of your CNN '''
maxtrain = max(map(float, record['train'][title]))
maxval = max(map(float, record['val'][title]))
ymax = max(maxtrain, maxval) * 1.1
mintrain = min(map(float, record['train'][title]))
minval = min(map(float, record['val'][title]))
ymin = min(mintrain, minval) * 0.9
total_steps = len(record['train'][title])
x_1 = list(map(int, record['train']['iter']))
x_2 = list(map(int, record['val']['iter']))
figure(figsize=(10, 6))
plt.plot(x_1, record['train'][title], c='tab:red', label='train')
plt.plot(x_2, record['val'][title], c='tab:cyan', label='val')
plt.ylim(ymin, ymax)
plt.xlabel('Training steps')
plt.ylabel(ylabel)
plt.title('Learning curve of {}'.format(title))
plt.legend()
plt.show()
In [11]
plot_learning_curve(loss_record, title='loss', ylabel='CE Loss')
<Figure size 1000x600 with 1 Axes>In [12]
plot_learning_curve(acc_record, title='acc', ylabel='Accuracy')
<Figure size 1000x600 with 1 Axes>In [13]
import time
work_path = 'work/model'model = inline_deit_tiny(num_classes=10)
model_state_dict = paddle.load(os.path.join(work_path, 'best_model.pdparams'))
model.set_state_dict(model_state_dict)
model.eval()
aa = time.time()for batch_id, data in enumerate(val_loader):
x_data, y_data = data
labels = paddle.unsqueeze(y_data, axis=1) with paddle.no_grad():
logits = model(x_data)
bb = time.time()print("Throughout:{}".format(int(len(val_dataset)//(bb - aa))))
Throughout:1137In [14]
def get_cifar10_labels(labels):
"""返回CIFAR10数据集的文本标签。"""
text_labels = [ 'airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck'] return [text_labels[int(i)] for i in labels]
In [15]
def show_images(imgs, num_rows, num_cols, pred=None, gt=None, scale=1.5):
"""Plot a list of images."""
figsize = (num_cols * scale, num_rows * scale)
_, axes = plt.subplots(num_rows, num_cols, figsize=figsize)
axes = axes.flatten() for i, (ax, img) in enumerate(zip(axes, imgs)): if paddle.is_tensor(img):
ax.imshow(img.numpy()) else:
ax.imshow(img)
ax.axes.get_xaxis().set_visible(False)
ax.axes.get_yaxis().set_visible(False) if pred or gt:
ax.set_title("pt: " + pred[i] + "\ngt: " + gt[i]) return axes
In [16]
work_path = 'work/model'X, y = next(iter(DataLoader(val_dataset, batch_size=18))) model = inline_deit_tiny(num_classes=10) model_state_dict = paddle.load(os.path.join(work_path, 'best_model.pdparams')) model.set_state_dict(model_state_dict) model.eval() logits = model(X) y_pred = paddle.argmax(logits, -1) X = paddle.transpose(X, [0, 2, 3, 1]) axes = show_images(X.reshape((18, 224, 224, 3)), 1, 18, pred=get_cifar10_labels(y_pred), gt=get_cifar10_labels(y)) plt.show()
[2025-12-11 17:32:01,453] [ WARNING] image.py:705 - Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Got range [-1.8952821..2.5877128]. [2025-12-11 17:32:01,457] [ WARNING] image.py:705 - Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Got range [-2.117904..2.500567]. [2025-12-11 17:32:01,461] [ WARNING] image.py:705 - Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Got range [-2.0494049..2.5877128]. [2025-12-11 17:32:01,465] [ WARNING] image.py:705 - Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Got range [-1.4842881..2.2739873]. [2025-12-11 17:32:01,469] [ WARNING] image.py:705 - Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Got range [-1.9980307..1.8158265]. [2025-12-11 17:32:01,473] [ WARNING] image.py:705 - Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Got range [-1.9656862..1.4954194]. [2025-12-11 17:32:01,476] [ WARNING] image.py:705 - Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Got range [-2.1007793..2.64]. [2025-12-11 17:32:01,480] [ WARNING] image.py:705 - Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Got range [-1.7582842..2.605142]. [2025-12-11 17:32:01,484] [ WARNING] image.py:705 - Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Got range [-1.7925336..2.3585434]. [2025-12-11 17:32:01,487] [ WARNING] image.py:705 - Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Got range [-1.7411594..2.5702837]. [2025-12-11 17:32:01,491] [ WARNING] image.py:705 - Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Got range [-1.6897851..1.9079742]. [2025-12-11 17:32:01,496] [ WARNING] image.py:705 - Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Got range [-1.9306722..2.5702837]. [2025-12-11 17:32:01,500] [ WARNING] image.py:705 - Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Got range [-1.9466565..1.4896734]. [2025-12-11 17:32:01,504] [ WARNING] image.py:705 - Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Got range [-2.117904..2.605142]. [2025-12-11 17:32:01,507] [ WARNING] image.py:705 - Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Got range [-2.117904..2.64]. [2025-12-11 17:32:01,511] [ WARNING] image.py:705 - Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Got range [-2.117904..2.500567]. [2025-12-11 17:32:01,515] [ WARNING] image.py:705 - Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Got range [-2.117904..2.622571]. [2025-12-11 17:32:01,519] [ WARNING] image.py:705 - Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Got range [-1.5280111..2.326275].
<Figure size 2700x150 with 18 Axes>
本文探讨了导致线性注意力和Softmax注意力性能差距的核心因素,识别并验证了这两种注意力机制之间存在的两大基本差异:单射性质和局部建模能力。
以上就是【NIPS 2025】弥合鸿沟:重新考虑Softmax和线性注意力的详细内容,更多请关注其它相关文章!
# 这一
# 可以优化的免费网站
# 推广网站图片和文案素材
# 大促营销推广方案
# 成都网站建设模板工具
# seo斗牛软件
# 网站优化前做什么准备好
# 马鞍山seo网络推广再营销
# 新疆北方建设集团网站
# 南通会计网站建设程序
# 招商网站建设请示
# 景中
# 较低
# 长程
# 两种
# python
# 提出了
# 一言
# 更强
# 所示
# 中文网
# fig
# latte
# igs
# red
# cos
# ai
# qq
# git
相关栏目:
【
行业新闻62819 】
【
科技资讯67470 】
相关推荐:
AMD称下半年AI显卡供应充足,不需要像NVIDIA那样加价抢购
酒店业将如何受益于人工智能的改变?
再也不怕「视频会议」尬住了!谷歌CHI顶会发布新神器Visual Captions:让图片做你的字幕助手
杀入生成式AI的亚马逊云科技,能否再次生成未来?
人工智能产业竞跑“未来赛道” 创新发展放大“赋能”效应
对话无界AI创始人长铗:AI的创业机会在应用层丨创新者Innovator
AI新视野,增长新势能,伙伴云受邀出席笔记侠创业讲真话AI峰会
下一个前沿:量子机器学习和人工智能的未来
报告称 70% 程序员已使用各种 AI 工具编程
可按用户语气自动回复消息,Zoom 推出基于生成式 AI 的新功能
微软面向AI初学者推出免费网络课程
人工智能大胆预测:银河系至少有2万个地球,36种外星文明
人工智能在交通领域的革新:智能解决方案彻底改变交通方式
2025VR&AR显示技术峰会视频解析: 歌尔光学展示最新一代VR/AR光学模组
售价14.99万起!小米汽车部分信息疑遭AI曝光,内部人士回应:网传图片明显经过处理,不可轻信
【趋势周报】全球人工智能产业发展趋势:OpenAI向美国专利局提交“GPT-5”商标申请
DeepMind推惊世排序算法,C++库忙更新!
新华社联合北大发布AI大模型评测:安全可靠成重点,360智脑表现优异
AI大模型产品集体奔赴高考考场,教育赛道的讯飞星火能赢吗?
如布科技发布新产品AI口袋学习机S12
机构:边缘AI或是当前预期差最大的AI方向
Midjourney创始人:AI应该成为人类思想的延伸
Ai智能机器人,chat-免注册登入,直接使用新版gpt4.0!
跟着AI大热的“光模块”到底是什么?
面向AI大模型,腾讯云首次完整披露自研星脉高性能计算网络
给小朋友最好的科技礼物:乐天派桌面机器人
苹果AIGC专利:可通过语音指令生成AR/VR虚拟场景
乐天派桌面机器人加入小米米家生态系统,实现与其他智能设备的互联
“技术+实践+生态”三箭齐发,京东方抢占物联网高地
腾讯AI首次模拟拼接三星堆文物,工作取得阶段性的成果
pixivFANBOX 更新运营规则,禁止通过外链绕开 AI 生成禁令
人工智能颠覆软件测试四大方式
RoboNeo操作教程
“电碳”技术提升碳排放监测精度
改变城市交通:智慧城市中的智能交通
500元一张的AI艺术二维码制作,详细教程来了!
280万条多模态指令-响应对,八种语言通用,首个涵盖视频内容的指令数据集MIMIC-IT来了
AI新风口?首个高质量「文生视频」模型Zeroscope引发开源大战:最低8G显存可跑
爱设计 AI 一键生成 PPT 工具上线:输入标题即可生成 PPT
“风乌”气象大模型科学家团队:用AI预报极端天气未来不是梦!
如何用AI重塑你的工作流(一)
AYANEO AIR 1S 掌机 7 月 9 日发布:R7 7840U + OLED 屏
航拍无人机怎么选?大疆无人机盘点推荐
调查显示:实际上没有那么多人在用 ChatGPT
推动综合能源服务高质量发展
ChatGPT大更新!OpenAI奉上程序员大礼包:API新增杀手级能力还降价,新模型、四倍上下文都来了
禁止艺术家使用 AI 创作《龙与地下城》游戏插图的决定已在 D&D Beyond 生效
湖北科技职业学院举行工业机器人及智能制造技术专精特新产业学院建设启动仪式
赋能金融新生态,多家银行创新应用成果亮相世界人工智能大会
为什么很多人对纽约《人工智能招聘法》感到生气?
 当前位置:
当前位置:  or imshow with RGB data ([0..1] for floats or [0..255] for integers). Got range [-1.9466565..1.4896734].
[2025-12-11 17:32:01,504] [ WARNING] image.py:705 - Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Got range [-2.117904..2.605142].
[2025-12-11 17:32:01,507] [ WARNING] image.py:705 - Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Got range [-2.117904..2.64].
[2025-12-11 17:32:01,511] [ WARNING] image.py:705 - Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Got range [-2.117904..2.500567].
[2025-12-11 17:32:01,515] [ WARNING] image.py:705 - Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Got range [-2.117904..2.622571].
[2025-12-11 17:32:01,519] [ WARNING] image.py:705 - Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Got range [-1.5280111..2.326275].
or imshow with RGB data ([0..1] for floats or [0..255] for integers). Got range [-1.9466565..1.4896734].
[2025-12-11 17:32:01,504] [ WARNING] image.py:705 - Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Got range [-2.117904..2.605142].
[2025-12-11 17:32:01,507] [ WARNING] image.py:705 - Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Got range [-2.117904..2.64].
[2025-12-11 17:32:01,511] [ WARNING] image.py:705 - Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Got range [-2.117904..2.500567].
[2025-12-11 17:32:01,515] [ WARNING] image.py:705 - Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Got range [-2.117904..2.622571].
[2025-12-11 17:32:01,519] [ WARNING] image.py:705 - Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Got range [-1.5280111..2.326275]. 上一篇:
上一篇: 返回列表
返回列表