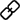400 128 6709

行业新闻
 发布时间:2025-07-28
发布时间:2025-07-28 点击次数:
点击次数: 本文介绍了文本的向量表示,包括词向量的概念、将单词转化为向量的方式及词向量具备语义信息的特点。还讲解了独热编码、词袋模型、TF-IDF、N-gram模型等离散表示方法,并指出离散表示存在无法衡量词间关系、数据稀疏、计算复杂等缺点。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜


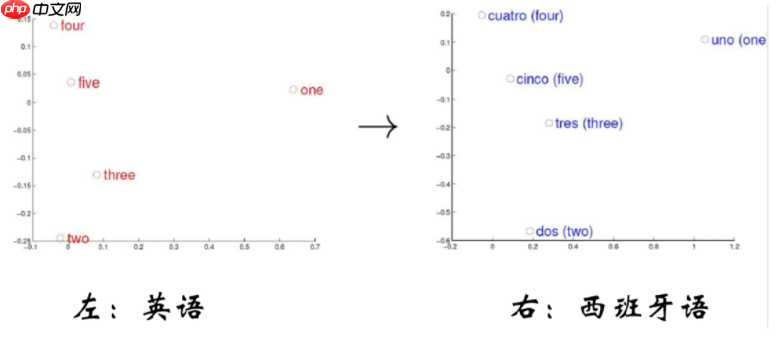
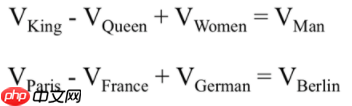
最终目标:单词的向量表示作为机器学习,特别是深度学习的输入和表示空间

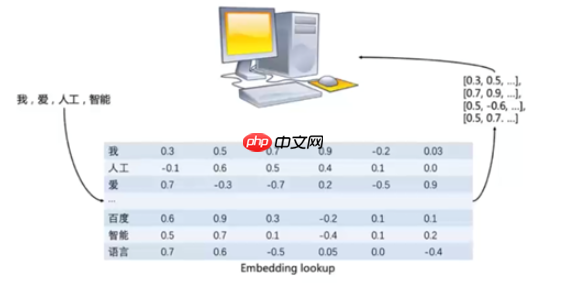

使用上下文可以推断出第一个“苹果”指的是iphone手机;
 MVM mall 网上购物系统
MVM mall 网上购物系统
采用 php+mysql 数据库方式运行的强大网上商店系统,执行效率高速度快,支持多语言,模板和代码分离,轻松创建属于自己的个性化用户界面 v3.5更新: 1).进一步静态化了活动商品. 2).提供了一些重要UFT-8转换文件 3).修复了除了网银在线支付其它支付显示错误的问题. 4).修改了LOGO广告管理,增加LOGO链接后主页LOGO路径错误的问题 5).修改了公告无法发布的问题,可能是打压
 0
查看详情
0
查看详情

深 1 0 0 0 度 0 1 0 0 学 0 0 1 0 习 0 0 0 1
# 实现one-hot encoder编码表示"""
性别 区域 成绩
0 0 3
1 1 0
0 2 1
1 0 2
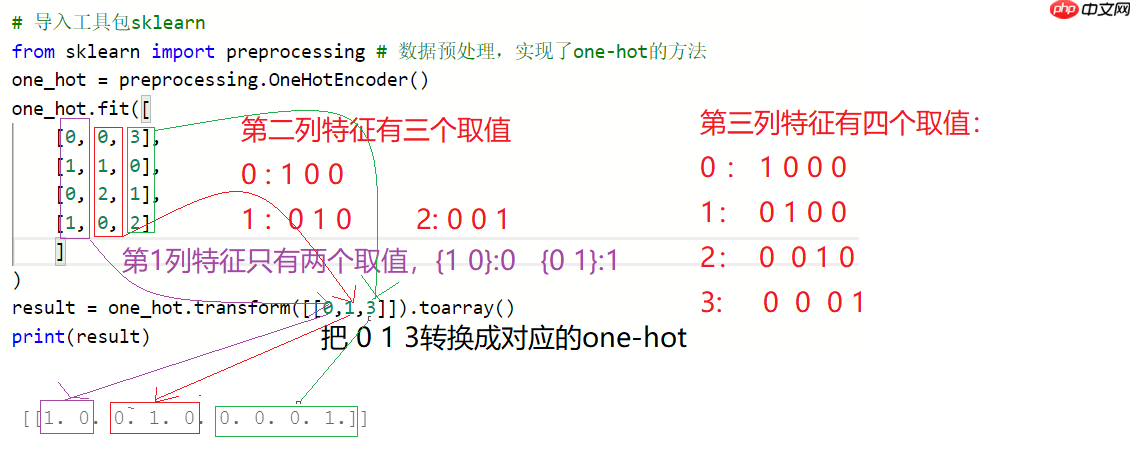
需求:请输出[0, 1, 3]每个数字的one-hot编码表示
"""# 导入工具包sklearnfrom sklearn import preprocessing # 数据预处理,实现了one-hot的方法one_hot = preprocessing.OneHotEncoder()
one_hot.fit([
[0, 0, 3],
[1, 1, 0],
[0, 2, 1],
[1, 0, 2]
]
)
result = one_hot.transform([[0,2,2]]).toarray()print(result)
[[1. 0. 0. 0. 1. 0. 0. 1. 0.]]
orange banana apple grape banana apple apple grapeorange apple
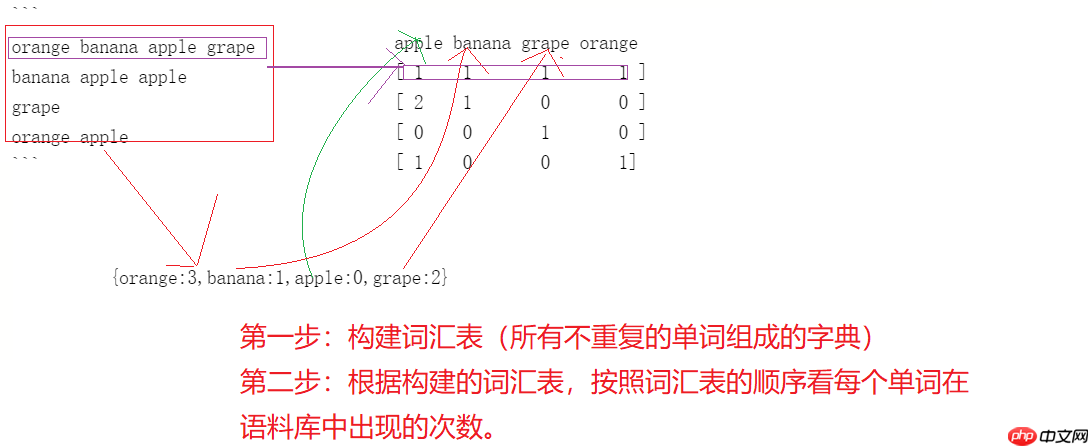
# 1. 导入工具库from sklearn.feature_extraction.text import CountVectorizer # 计数texts = [ "orange banana apple grape", "banana apple apple apple", "grape", "orange apple", ] count_vec = CountVectorizer() # 创建词袋模型的对象count_vec_fit = count_vec.fit_transform(texts) # 训练语料库print(count_vec.vocabulary_) # 输出根据语料库构建的词汇表print(count_vec_fit.toarray()) # 把文本转换成对应的向量表示
{'orange': 3, 'banana': 1, 'apple': 0, 'grape': 2}
[[1 1 1 1]
[3 1 0 0]
[0 0 1 0]
[1 0 0 1]]
In [12]注意事项:如果一个单词在句子中出现的频率非常的高,说明该单词具有一定的重要性,但如果一个词语在整篇语料库中出现的频率都很高,就说明这个单词很普遍(常见)。
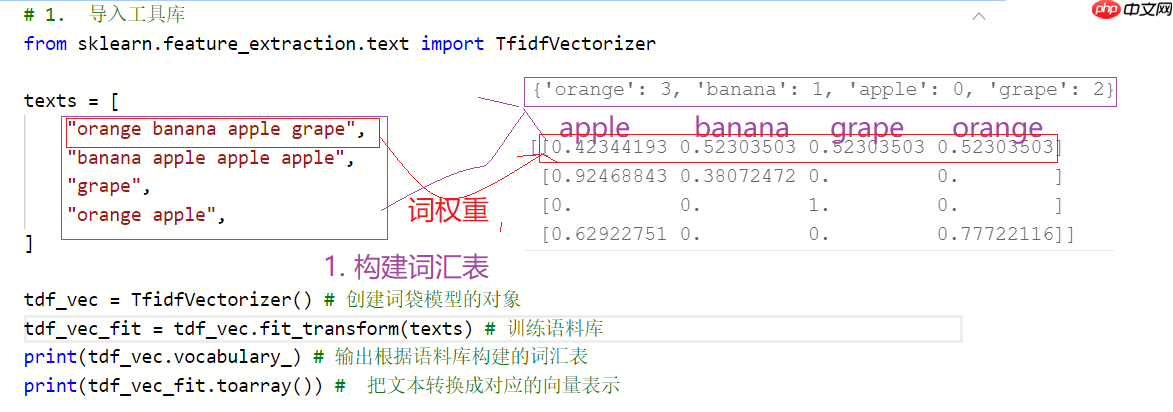
# 1. 导入工具库from sklearn.feature_extraction.text import TfidfVectorizer texts = [ "orange banana apple grape", "banana apple apple apple", "grape", "orange apple", ] tdf_vec = TfidfVectorizer() # 创建词袋模型的对象tdf_vec_fit = tdf_vec.fit_transform(texts) # 训练语料库print(tdf_vec.vocabulary_) # 输出根据语料库构建的词汇表print(tdf_vec_fit.toarray()) # 把文本转换成对应的向量表示
{'orange': 3, 'banana': 1, 'apple': 0, 'grape': 2}
[[0.42344193 0.52303503 0.52303503 0.52303503]
[0.92468843 0.38072472 0. 0. ]
[0. 0. 1. 0. ]
[0.62922751 0. 0. 0.77722116]]
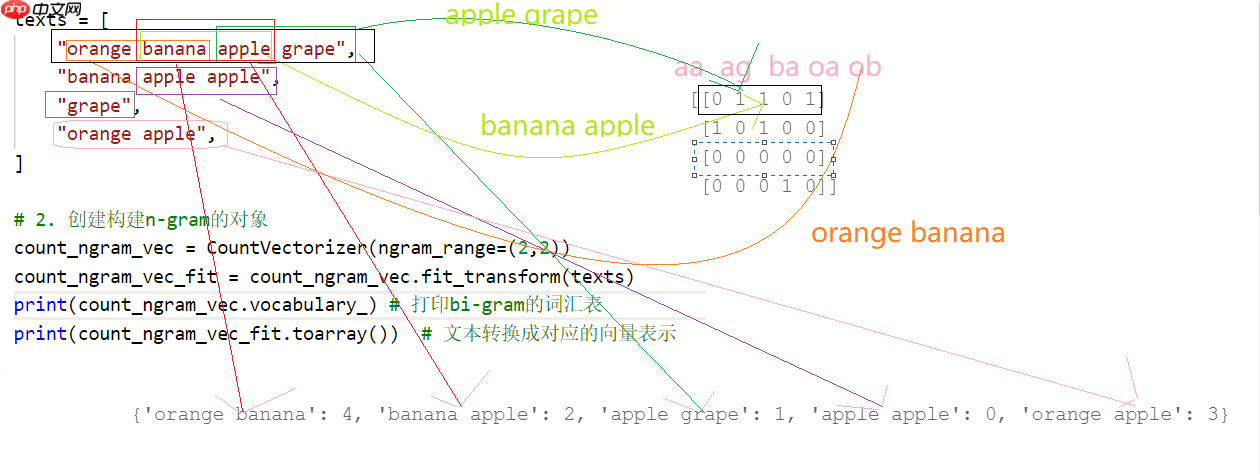
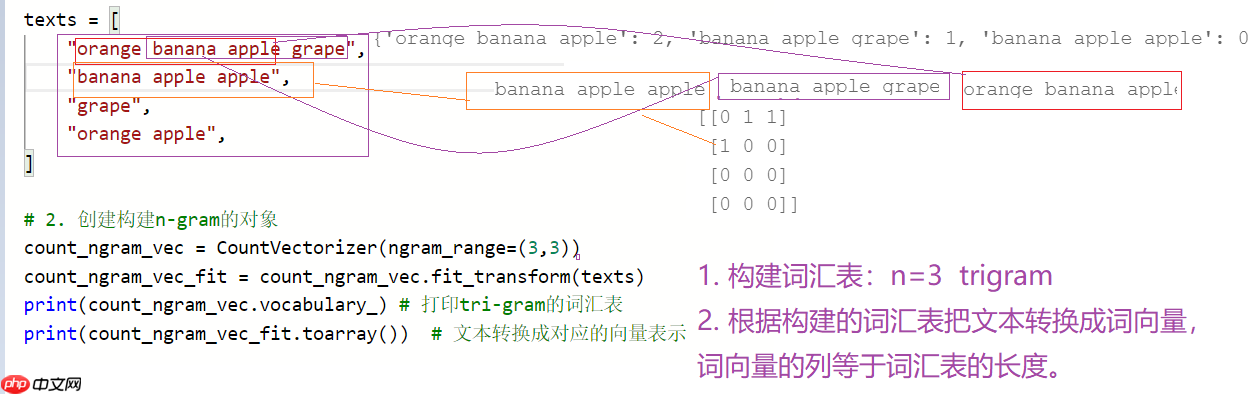
from sklearn.feature_extraction.text import CountVectorizer # 词频的统计可以实现n-gram# 1. 构建语料库texts = [ "orange banana apple grape", "banana apple apple", "grape", "orange apple", ]# 2. 创建构建n-gram的对象count_ngram_vec = CountVectorizer(ngram_range=(2,3)) count_ngram_vec_fit = count_ngram_vec.fit_transform(texts)print(count_ngram_vec.vocabulary_) # 打印bi-gram的词汇表print(count_ngram_vec_fit.toarray()) # 文本转换成对应的向量表示
{'orange banana': 6, 'banana apple': 2, 'apple grape': 1, 'orange banana apple': 7, 'banana apple grape': 4, 'apple apple': 0, 'banana apple apple': 3, 'orange apple': 5}
[[0 1 1 0 1 0 1 1]
[1 0 1 1 0 0 0 0]
[0 0 0 0 0 0 0 0]
[0 0 0 0 0 1 0 0]]
酒店 1 0 0 宾馆 0 1 0 旅社 0 0 1
以上就是文本离散表示方法的详细内容,更多请关注其它相关文章!
# 自然语言
# 织梦网站url优化
# 家乡特产推广营销
# 正规网站建设公司代理
# seo营销有什么好处
# 商丘关键词排名优化
# seo专员职位职责
# 余姚外贸网站制作推广
# 搜索引擎网络营销的推广
# 找家居网站建设
# 一个APP的推广运用什么营销方式
# 库中
# iphone
# 是一种
# 转换成
# 的是
# 购物系统
# 指的是
# 词汇表
# 华为
# 中文网
# iphone手机
# 苹果
# 工具
相关栏目:
【
行业新闻62819 】
【
科技资讯67470 】
相关推荐:
报告称 70% 程序员已使用各种 AI 工具编程
「从未被制造出的最重要机器」,艾伦·图灵及图灵机那些事
谷歌StyleDrop在可控性上卷翻MidJourney,前GitHub CTO用AI颠覆编程
研究发现AI聊天机器人ChatGPT不会讲笑话,只会重复25个老梗
甲骨文与Cohere合作为企业提供生成式人工智能服务
7条线路感受智慧美好生活,“2025 世界人工智能大会民营企业社会开放日”主题活动启动
解决导航“最后50米”难题 高德地图升级AR步行导航找终点功能
XREAL Beam 投屏盒子正式发布:支持“可悬停 AR 空间屏”
猿辅导发布最新SaaS业务进展公告:Motiff UI设计工具推出三项新的AI功能
新华全媒+|AI:当心,我可能欺骗了你!
微软 Copilot 团队主管呼吁用户与 AI 交流时应使用恰当的礼貌用语
美图公司:Wink国内首发AI画面拓展功能
Meta 发布 Voicebox AI 模型:可生成音频信息,用于 NPC 对话等
AYANEO AIR 1S 掌机 7 月 9 日发布:R7 7840U + OLED 屏
【原创】奥比中光:与英伟达合作开发的3D开发套件正式发布 连接英伟达AI应用生态
元宇宙迈入2.0时代,它和生成式人工智能有何关联吗?
不止“文心一言”,消息称百度将推出全新 AI 对话软件“万话”
寻求能源转型最优解
揭示经济学论文写作中提高效率与质量的AI助手应用策略
AI生成会议纪要 百度如流升级推出超级助手、智能编码等功能
两架海燕号无人机交付中国气象局 助力建设国家级机动气象观测业务
能走、能飞、能游泳,科学家打造全能 M4 机器人
丰田汽车研究院推出生成式人工智能汽车设计工具
海南科技职业大学第25届中国机器人及人工智能大赛海南赛区荣获一等奖等114项
7/8上海 | 2025世界人工智能大会分论坛:科技与人文-共筑无障碍智能社会
鹅厂机器狗抢起真狗「饭碗」!会撒欢儿做游戏,遛人也贼6
腾讯自主研发机器狗 Max 升级,可“奔跑跳跃”完成避障动作
人工智能即将进入Windows:企业准备好安全策略设置了吗?
构建数字文旅新高地!洛阳涧西区开启元宇宙时代
智能客服进入AI 2.0时代 容联云发布语言大模型“赤兔”
机器人 展才能
猿辅导推出Motiff,整合三大AI功能,助力UI设计生产力革新
智能电网技术:提高能源效率和可靠性
深度学习模型综述:用于3D MRI和CT扫描的应用
全新小艺搭载AI大模型,有效提升学生和职场人士的工作效率
V社悄悄封禁使用AI生成美术素材的游戏
Meta 人工智能业务落后竞争对手,研究人员大量离职成重要原因
阿里达摩院向公众免费开放100项AI专利许可
微软AR/VR专利提出使用时间复用谐振驱动产生双极性电源
OpenAI宣布在伦敦设立海外分部,要招揽“世界级人才”
静安大宁功能区企业云天励飞亮相2025世界人工智能大会,秀出AI硬实力!
音乐制作元工具AudioCraft发布开源AI工具
物联网和人工智能的协同作用:释放预测性维护的潜力
靠游戏更靠AI 英伟达成唯一首季度两位数增长的公司
编程已死,AI 当立?教授公开“唱反调”:AI 还帮不了程序员
海柔创新携手SAP,以机器人技术助力全球客户升级数智化竞争力
花16000元买四款扫拖机器人!科沃斯追觅石头小米谁能笑到最后?
看似低调,实则稳健:字节在AI路上会遇到什么?
建立元宇宙产业联盟:移动、咪咕、华为、小米等加入
马斯克回应“人工智能让一切变得更好”:我们已经是半机器人了
 当前位置:
当前位置:  汇表print(count_ngram_vec_fit.toarray()) # 文本转换成对应的向量表示
汇表print(count_ngram_vec_fit.toarray()) # 文本转换成对应的向量表示 上一篇:
上一篇: 返回列表
返回列表