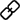400 128 6709

行业新闻
 发布时间:2025-07-25
发布时间:2025-07-25 点击次数:
点击次数: 本地演示视频(手机版貌似看不到,在codelab里也没法直接看到,只有网页版的项目预览可以看到)
视频传送门
gitee仓库
社区是城市的关键组成部分,社区治理是围绕社区场景下的人、地、物、情、事的管理与服务。
随着城市化的快速推进及人口流动的快速增加,传统社区治理在人员出入管控、安防巡逻、车辆停放管理等典型场景下都面临着人力不足、效率低下、响应不及时等诸多难题。而人工智能技术代替人力,实现人、车、事的精准治理,大幅降低人力、物质、时间等成本,以最低成本发挥最强大的管理效能,有效推动城市治理向更“数字化、自动化、智慧化”的方向演进。
传统社区视频监控80%都依靠人工实现,随着摄像头在社区中的大规模普及,日超千兆的视频图像数据、人员信息的日渐繁杂已远超人工的负荷。
为解决以上问题,我们灵活应用飞桨行人分析PP-Human中的行人检测和属性分析模型,实时识别行人的性别、年龄、衣着打扮等26种属性并记录统计。
其中,属性分析包含26种不同属性:
- 性别:男、女- 年龄:小于18、18-60、大于60- 朝向:朝前、朝后、侧面- 配饰:眼镜、帽子、无- 正面持物:是、否- 包:双肩包、dan肩包、shou提包- 上衣风格:带条纹、带logo、带格子、拼接风格- 下装风格:带条纹、带图案- 短袖上衣:是、否- 长袖上衣:是、否- 长外套:是、否- 长裤:是、否- 短裤:是、否- 短裙&裙子:是、否- 穿靴:是、否

PP-Human是基于飞桨深度学习框架的业界首个开源的实时行人分析工具,具有功能丰富,应用广泛和部署高效三大优势。PP-Human 支持图片/单镜头视频/多镜头视频多种输入方式,功能覆盖多目标跟踪、属性识别和行为分析。能够广泛应用于智慧交通、智慧社区、工业巡检等领域。支持服务器端部署及TensorRT加速,T4服务器上可达到实时。
详细文档可参考:https://github.com/PaddlePaddle/PaddleDetection/tree/develop/deploy/pphuman
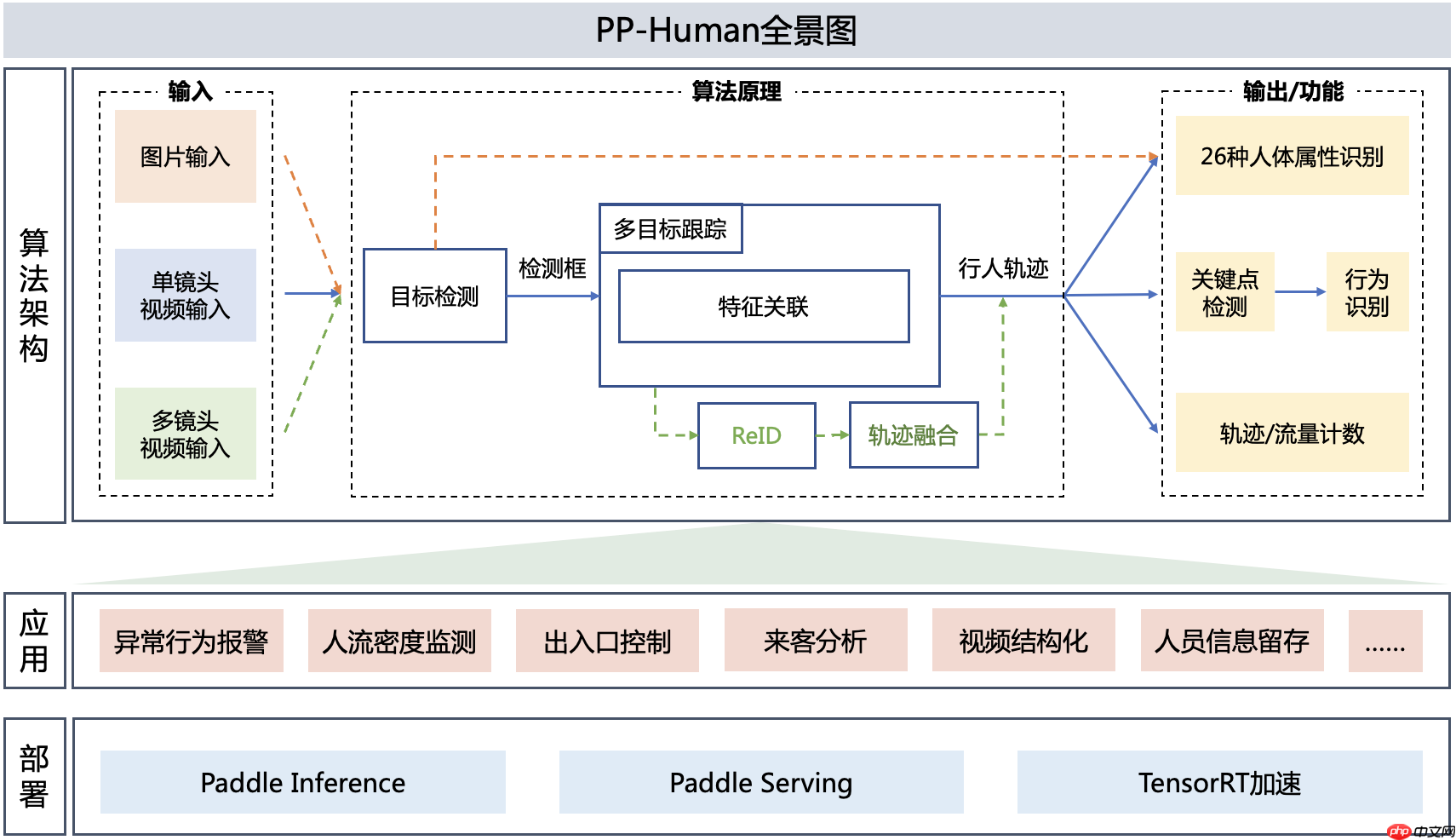
在本项目中,我们基于PP-HUMAN实现一套行人客流和人员属性统计系统,可以通过数据库查询,有可视化统计页面。
1.2.1.识别:使用PP-HUMAN的行人属性检测方案,对于视频流的行人属性识别需要用到MOT(多目标跟踪)模型和ATTR(行人属性识别)模型,由MOT模型识别并跟踪行人,由ATTR模型进行多分类识别行人属性。
1.2.2.后端:
Flask是一个轻量级的可定制框架,使用Python语言编写,较其他同类型框架更为灵活、轻便、安全且容易上手。它可以很好地结合MVC模式进行开发,开发人员分工合作,小型团队在短时间内就可以完成功能丰富的中小型网站或Web服务的实现。另外,Flask还有很强的定制性,用户可以根据自己的需求来添加相应的功能,在保持核心功能简单的同时实现功能的丰富与扩展,其强大的插件库可以让用户实现个性化的网站定制,开发出功能强大的网站。(百度百科) 总而言之flask用python编写,对于技术栈还不够全面和足够熟练的新手小队实现起来方便一些。
1.2.3.前端:
1.2.3.1.Ajax:
Asynchronous J*ascript And XML(异步J*aScript和XML)是一种web数据交互方式,使用Ajax技术网页应用能够快速地将增量更新呈现在用户界面上,而不需要重载(刷新)整个页面,这使得程序能够更快地回应用户的操作。用来实时刷新数据。
1.2.3.2.ECharts:
ECharts是一款基于J*aScript的数据可视化图表库,提供直观,生动,可交互,可个性化定制的数据可视化图表。
1.2.4.数据库:
SQLite是一款轻型的数据库,是遵守ACID的关系型数据库管理系统,它包含在一个相对小的C库中。它的设计目标是嵌入式的,而且已经在很多嵌入式产品中使用了它,它占用资源非常的低,在嵌入式设备中,可能只需要几百K的内存就够了。技术成熟、资源占用少并且可以直接在python中import直接使用,有SQL知识基础的小伙伴上手很快。
PETA (PEdesTrian Attribute)数据集包含了8705个行人,共19000张图像(分辨率跨度范围大,从17x39到169x365的大小都有)。每个行人标注了61个二值的和4个多类别的属性。
环境要求: PaddleDetection版本 >= release/2.4 或 develop
git clone https://gitee.com/paddlepaddle/PaddleDetection.git
%cd /home/aistudio/# 克隆PaddleDetection仓库# !git clone https://gitee.com/paddlepaddle/PaddleDetection.git!unzip PaddleDetection.zipIn [ ]
# 安装其他依赖%cd PaddleDetection !pip install -r requirements.txtIn [ ]
# 可选,安装paddledet!python setup.py install
该zip中包含flask后端代码app.py、前端数据可视化代码index.html、前端js库以及整合适配后的推理相关代码。
In [ ]#更换为修改过的pphuman文件夹!rm -rf /home/aistudio/PaddleDetection/deploy/pphuman !unzip /home/aistudio/pphuman.zip -d /home/aistudio/PaddleDetection/deploy/pphuman
PPHuman中实现整个行人分析的工具和部署流程,包括检测、多目标跟踪、跨镜头跟踪、关键点检测、行为识别等多个模块。在这一部分中, 我们以关键点模型为例,展示将dark_hrnet_w32_256x192这一个模型从训练到导出至部署可用的模型的全流程。详细细节可以参考我们的Github文档。
训练模型主要包括准备训练数据以及启动训练命令,可以按照下面的命令执行。
这里由于完整COCO数据集的训练耗时较长,我们准备了一个样例数据集,供执行流程参考使用。
In [ ]# 准备我们的样例训练数据%cd /home/aistudio/PaddleDetection/ !wget https://bj.bcebos.com/v1/paddledet/data/keypoint/coco_val_person_mini.tar !tar -xf coco_val_person_mini.tar -C ./dataset/ !mv ./dataset/coco_val_person_mini/* ./dataset/coco !cp ./dataset/coco/annotations/instances_train2017.json ./dataset/coco/annotations/person_keypoints_train2017.json !cp ./dataset/coco/annotations/instances_val2017.json ./dataset/coco/annotations/person_keypoints_val2017.jsonIn [ ]
#训练模型, 如果是CPU环境,请加上 -o use_gpu=False%cd /home/aistudio/PaddleDetection/ !python tools/train.py -c configs/keypoint/hrnet/dark_hrnet_w32_256x192.yml
完成训练后,我们的模型默认保存在output/dark_hrnet_w32_256x192/。
在训练模型以后,我们可以通过运行评估命令来得到模型的精度,以确认训练的效果。评估可以参考以下命令执行。
这里使用了我们已经训练好的模型。如希望使用自己训练的模型,请对应将weights=后的值更改为对应模型.pdparams文件的存储路径。
 简小派
简小派
简小派是一款AI原生求职工具,通过简历优化、岗位匹配、项目生成、模拟面试与智能投递,全链路提升求职成功率,帮助普通人更快拿到更好的 offer。
 123
查看详情
123
查看详情
 In [ ]
In [ ]
!python tools/eval.py -c configs/keypoint/hrnet/dark_hrnet_w32_256x192.yml \ -o weights=https://paddledet.bj.bcebos.com/models/keypoint/dark_hrnet_w32_256x192.pdparams
.pdparams只包括了模型的参数数据,实际部署还需要执行导出步骤。导出步骤可以参考下面列举的步骤:
注意,这里使用了我们已经训练好的模型。如希望使用自己训练的模型,请对应将weights=后的值更改为对应模型.pdparams文件的存储路径。如果没有指定--output_dir,那么导出的模型将默认存储在output_inference/路径下。
In [ ]!python tools/export_model.py -c configs/keypoint/hrnet/dark_hrnet_w32_256x192.yml \ --output_dir inference_models/ \ -o weights=https://paddledet.bj.bcebos.com/models/keypoint/dark_hrnet_w32_256x192.pdparams
至此,我们就完成了关键点模型的从训练到导出的过程。可以用于PPhuman的实际部署中了。
参考以上步骤,在我们PaddleDetection套件中,除了关键点检测以外,同样可以实现检测、跟踪模型的训练、评估及导出使用。
行为识别模型从训练到到导出使用的全流程介绍及对应源码,细节请参考 PP-Human 行为识别模型。
行为识别模型本质上是一个分类模型,如果用户希望训练自定义的行为类型,可以参照以下步骤执行:
在这一步中,逐一下载上述我们事先为大家准备的各任务的导出模型,可以直接使用。如果您希望在自己的场景上进一步迭代优化,也可以参考前述如何构建模型部分,完成对应模块模型的训练到导出流程,得到部署需要的导出模型。
In [ ]#下载检测模型!wget https://bj.bcebos.com/v1/paddledet/models/pipeline/mot_ppyoloe_l_36e_pipeline.zip#下载属性模型!wget https://bj.bcebos.com/v1/paddledet/models/pipeline/strongbaseline_r50_30e_pa100k.zip#下载关键点模型#!wget https://bj.bcebos.com/v1/paddledet/models/pipeline/dark_hrnet_w32_256x192.zip#下载行为识别模型#!wget https://bj.bcebos.com/v1/paddledet/models/pipeline/STGCN.zipIn [ ]
#解压至./output_inference文件夹!unzip -d output_inference mot_ppyoloe_l_36e_pipeline.zip!unzip -d output_inference strongbaseline_r50_30e_pa100k.zip#!unzip -d output_inference dark_hrnet_w32_256x192.zip#!unzip -d output_inference STGCN.zip
PP-Human相关配置位于deploy/pphuman/config/infer_cfg.yml中,存放模型路径,完成不同功能需要设置不同的任务类型。
功能及任务类型对应表单如下:
| 输入类型 | 功能 | 任务类型 | 配置项 |
|---|---|---|---|
| 图片 | 属性识别 | 目标检测 属性识别 | DET ATTR |
| 单镜头视频 | 属性识别 | 多目标跟踪 属性识别 | MOT ATTR |
| 单镜头视频 | 行为识别 | 多目标跟踪 关键点检测 行为识别 | MOT KPT ACTION |
本项目应用到的是:
我们以一个视频文件来展示一下属性识别的实际使用方式。
在预测命令中,模型预测参数选择分为两部分:
例如,我们可以增加下列命令,指定检测模型和属性识别模型的路径:
--model_dir det=output_inference/mot_ppyoloe_l_36e_pipeline/ attr=output_inference/strongbaseline_r50_30e_pa100k/
支持开发者根据具体情况选择视频或单帧图片输入进行属性识别。
注意事项:
#补充安装相关库(不然运行下面的)视频行人属性识别指令会报错缺库!pip install motmetrics !pip install lapIn [ ]
#视频行人属性识别#pipeline.py里的attr_res是视野里识别出的标签#处理结果可在/home/aistudio/PaddleDetection/output/ 中查看!python deploy/pphuman/pipeline.py \
--config deploy/pphuman/config/infer_cfg.yml \
--model_dir mot=output_inference/mot_ppyoloe_l_36e_pipeline/ attr=output_inference/strongbaseline_r50_30e_pa100k/ \
--video_file=/home/aistudio/属性.mp4 \
--enable_attr=True \
--device=gpu
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

#图片行人属性识别#处理结果可在/home/aistudio/PaddleDetection/output/ 中查看!python deploy/pphuman/pipeline.py \
--config deploy/pphuman/config/infer_cfg.yml \
--model_dir det=output_inference/mot_ppyoloe_l_36e_pipeline/ attr=output_inference/strongbaseline_r50_30e_pa100k/ \
--image_dir=/home/aistudio/photodemo \
--enable_attr=True \
--device=gpu
NVIDIA TensorRT是一个高性能的深度学习预测库。PP-Human同样支持了使用TensorRT加速模型的预测,并且整个步骤十分简单快速。您可以参考以下步骤实现:
(记录了一些踩的坑,菜菜遇到坑只会搜索)
1.: cannot connect to X server !
原因:在BML CodeLab中没有允许实时显示可视化视频的权限,故在BML CodeLab中只能注释掉PaddleDetection/deploy/pphuman/pipeline.py里的(已经注释掉,本地使用建议解开注释)
#在BML CodeLab中无法实时显示,故注释下面三行cv2.imshow('PPHuman', im)if cv2.waitKey(1) & 0xFF == ord('q'): break
ctrl+f搜索,将两个位置的上面三行注释后再次运行即可运行对视频的检测。(本地的打开显示预测处理结果是没有问题的)
2.重新annaconda配置环境
3.遇到报错ERROR: Failed building wheel for pycocotools
4.发现系统没有cudnn,配置教程
5.cudnn库报错缺dll文件
6.mysql主键唯一键重复插入解决方法
7.视频流传输
! python /home/aistudio/PaddleDetection/deploy/pphuman/app.py# 这个在BML CodeLab目前同样无法查看,后端起的服务在环境本地,从我们的浏览器CodeLab访问不了,部署到本地是可以看到的。
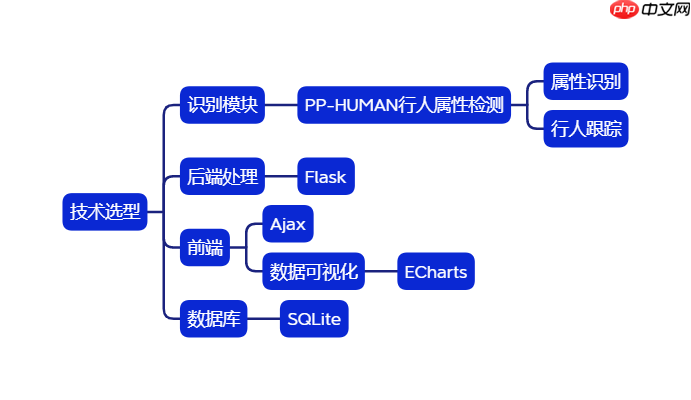
本地服务效果如图
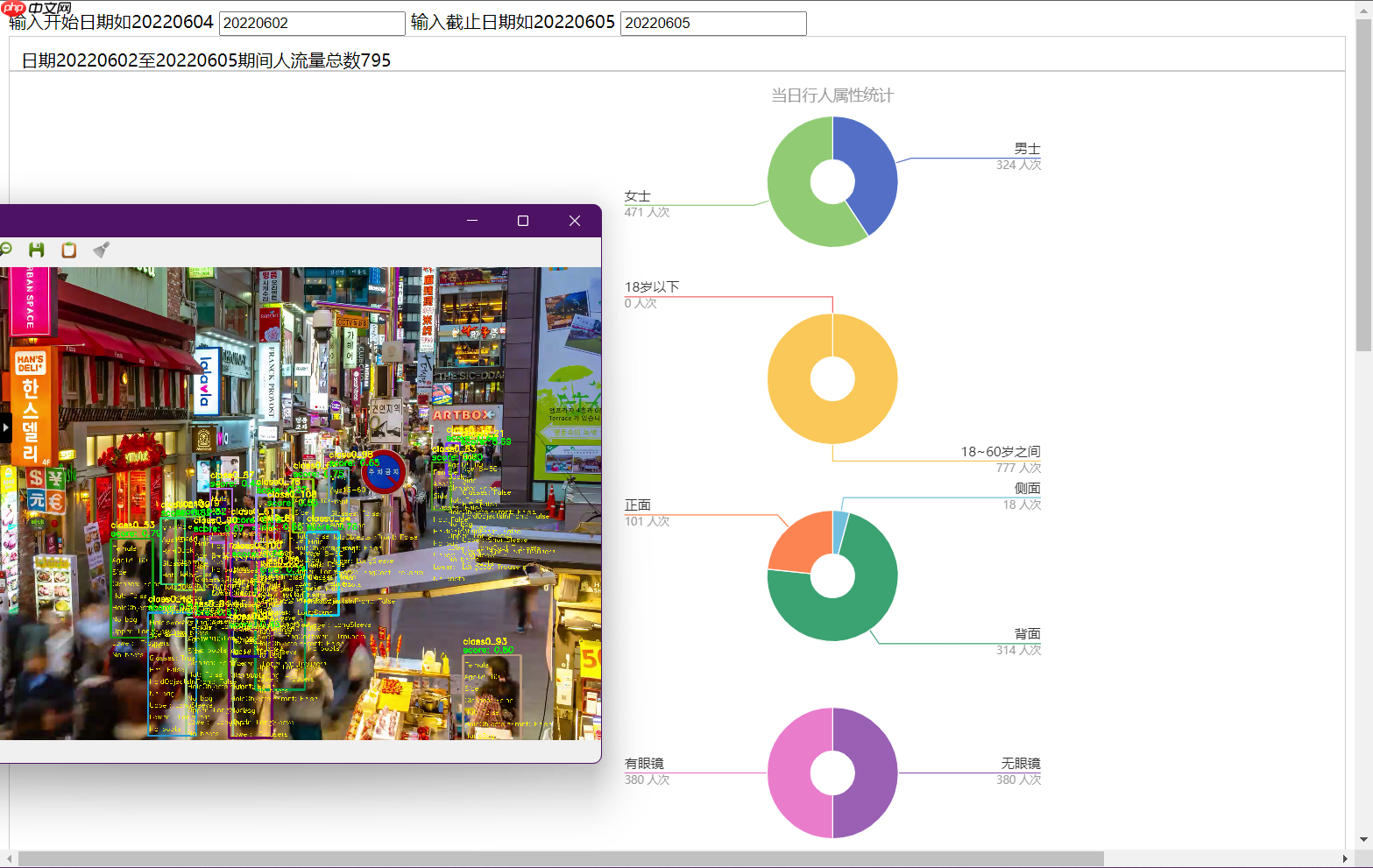
以上就是【校园AI Day-AI workshop】基于PP-HUMAN的客流及属性统计的详细内容,更多请关注其它相关文章!
# 配置文件
# 网站的优化设计高中学习
# SEO做得出色的网站
# 营销推广选择什么行业好
# 个人网站建设源码是什么
# 盐城红书营销推广
# 贵港网站建设模板招标公告
# 定西抖音seo推广
# 成都seo哪家价格
# 潼南区的高效网站建设
# 如何优化网站界面设计
# 在这
# 自然语言
# 开源
# 报错
# 自定义
# mysql
# 是一个
# 自己的
# 中文网
# fig
# whee
# udio
# igs
# 百度
# 解决方法
# ai
# 工具
# 浏览器
# docker
# git
# python
相关栏目:
【
行业新闻62819 】
【
科技资讯67470 】
相关推荐:
鸿蒙智能座舱的AI大模型革新,引领智能座舱领域的变革吗?
煤电“三改联动”需多措联动
AI立法迫在眉睫,如何看对行业影响?
真全息产品,亮相深圳文博会——dipal数伴拓展元宇宙非沉浸式体验
苹果在韩举办首届中小企业智能制造论坛,加速推动工业4.0发展
世界人工智能大会(WAIC 2025)点燃魔都,博尔捷数字科技携前沿技术产品亮相
明略科技发布免费开源TensorBoard.cpp,促进大型模型的预训练工作
物联网和人工智能的协同作用:释放预测性维护的潜力
特斯拉机器人面世 未来将大幅提振磁材需求,引领人工智能时代
从数据中心到发电站:人工智能对能源使用的影响
百度创始人、董事长兼首席执行官李彦宏:AI原生应用比大模型数量更重要
新华三集团总裁兼首席执行官于英涛:人工智能时代需要想象力,更需要精耕务实
英伟达H100霸榜权威AI性能测试 11分钟搞定基于GPT-3的大模型训练
工信部信通院发布《2025大模型和AIGC产业图谱》 360智脑覆盖全产业链
一句话搞定数据分析,浙大全新大模型数据助手,连搜集都省了
能抓取玻璃碎片、水下透明物,清华提出通用型透明物体抓取框架,成功率极高
人工智能改变网络安全和用户体验的三种方式
Snow Kylin登陆中国列车,打造全球首条元宇宙专列
AI行业盛会大咖云集!Sam Altam、“AI教父”......一文看懂最新观点
大模型新品出现井喷,AI产业迎来新时代
美踏控股推出创新人工智能大数据模型“心乐舞河”:虚拟人音舞社交的新体验
OpenAI限制网络爬虫访问以保护数据免被用于AI模型训练
Spotify计划推出AI驱动的音乐播放器功能
意大利警察拟用AI预测犯罪 该算法被指种族歧视严重
谷歌推出 AI 反洗钱工具,可将金融机构内部风险预警准确率提高2至4倍
ChatGPT会成为你家新的语音助手吗?
国内AI大模型“安卓时刻”到来!阿里云通义千问免费、开源、可商用
警惕!AI或致虚假信息泛滥
Databricks推出人工智能模型共享机制,可令开发者与公司“双赢”
三星加速AR眼镜进程,预计明年上半年亮相
谷歌旗下 DeepMind 开发出 RoboCat AI 模型,能控制多种机器人执行一系列任务
“聚智启新,‘蓉’力同行” 成都市人工智能产业融通对接会成功举办
2025世界人工智能大会成功召开
人工智能行业急缺人 AI人才年薪能达近42万元
宇宙探索下一阶段,机器代替人类,AI会在太空探索中取代人类吗?
Bing 聊天机器人现支持在桌面端用语音提问
即将到来:AI婚纱设计软件实际测试,人工智能即将开创婚纱设计新纪元
花16000元买四款扫拖机器人!科沃斯追觅石头小米谁能笑到最后?
中国AI公有云市场2025年逆势蓬勃增长,增速高达80.6%
苹果CEO库克:持续研究生成式人工智能技术
BLIP-2、InstructBLIP稳居前三!十二大模型,十六份榜单,全面测评「多模态大语言模型」
了解 AGI:智能的未来?
当一个网站的内容被 AI 完全接管
2025“春晖杯”人工智能专场对接活动举办
GPT-4使用混合大模型?研究证明MoE+指令调优确实让大模型性能超群
iPhone两秒出图,目前已知的最快移动端Stable Diffusion模型来了
OpenAI 已全面开放 GPT-3.5 Turbo、DALL-E 及 Whisper API
选对AI智能写作软件,让创作游刃有余!
揭示经济学论文写作中提高效率与质量的AI助手应用策略
WHEE安装教程
 当前位置:
当前位置:  /train.py -c configs/keypoint/hrnet/dark_hrnet_w32_256x192.yml
/train.py -c configs/keypoint/hrnet/dark_hrnet_w32_256x192.yml 上一篇:
上一篇: 返回列表
返回列表