400 128 6709

行业新闻
 发布时间:2025-04-27
发布时间:2025-04-27 点击次数:
点击次数: kimi-audio 是由 moonshot ai 推出的开源音频基础模型,专注于音频理解、生成和对话任务。它在超过 1300 万小时的多样化音频数据上进行预训练,具备强大的音频推理和语言理解能力。其核心架构采用混合音频输入(连续声学 + 离散语义标记),结合基于 llm 的设计,支持并行生成文本和音频标记,同时通过分块流式解码器实现低延迟音频生成。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
Kimi-Audio的主要功能包括:
Kimi-Audio的技术原理包括:
Kimi-Audio的项目地址为:
 Figma
Figma
Figma 是一款基于云端的 UI 设计工具,可以在线进行产品原型、设计、评审、交付等工作。
 1371
查看详情
1371
查看详情

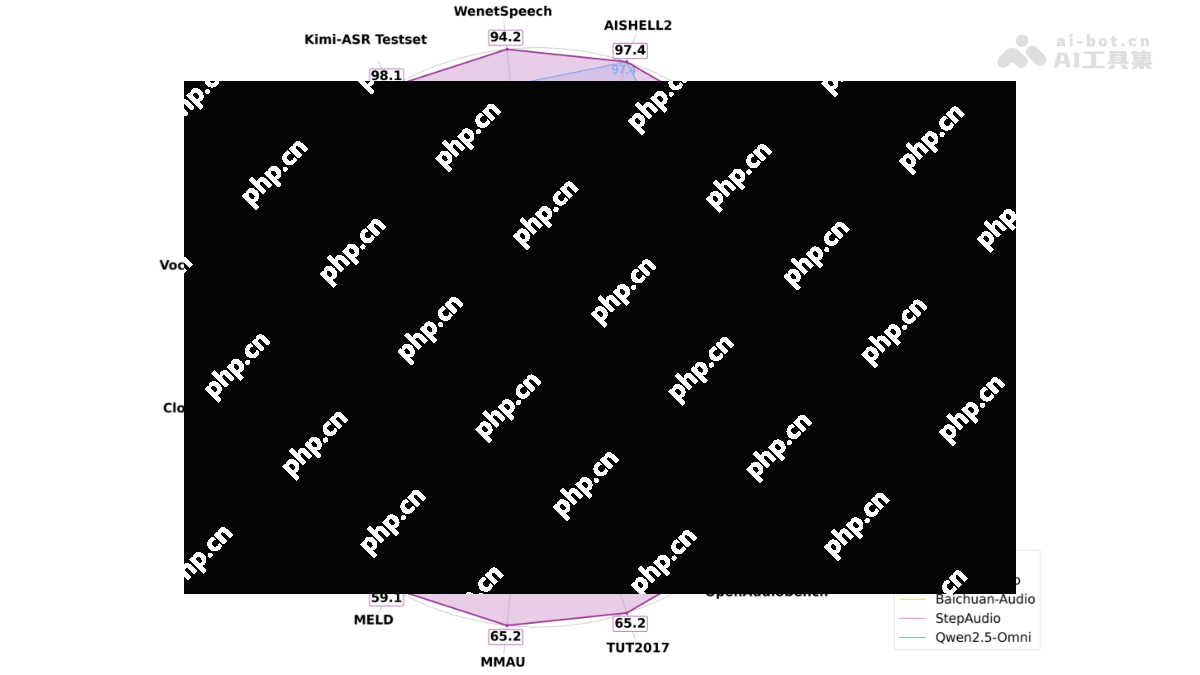
Kimi-Audio的性能表现包括:
Kimi-Audio的应用场景包括:
 并生成自然流畅的语音回应。
并生成自然流畅的语音回应。以上就是Kimi-Audio— Moonshot AI 开源的音频基础模型的详细内容,更多请关注其它相关文章!
# ai
# 东莞如何选择网站推广
# 贴吧关键词排名掉了怎么回事
# 河北信息网站建设职责
# 有哪些网站性能优化
# 湖州网站建设推广哪家好
# 网站建设 济南
# 甜品店营销推广策略
# 流式
# 适用于
# 客服
# 多个
# 流畅性
# 高质量
# 语音识别
# 开源
# 转换为
# 达到了
# peech
# udio
# qwen
# git
# 外贸网站推广思路怎么写
# 做网站优化价格高吗知乎
# 武汉企业网站优化方案
相关栏目:
【
行业新闻62819 】
【
科技资讯67470 】
相关推荐:
三星加速AR眼镜进程,预计明年上半年亮相
笔神作文声讨学而思AI大模型 称用“爬虫”技术盗取数据
类GPT模型训练提速26.5%,清华朱军等人用INT4算法加速神经网络训练
高质量数据推动AI场景化应用快速发展及落地
Databricks推出人工智能模型共享机制,可令开发者与公司“双赢”
机器人 展才能
人形机器人概念集体爆发,能买吗?
走进首家“元宇宙”未来工厂,卡奥斯探知工业之旅出发!
Meta开源文本生成音乐大模型,我们用《七里香》歌词试了下
人工智能在项目管理中的作用
张朝阳与陆川谈AI:ChatGPT是鹦鹉学舌思维,不可能取代人类 | 把脉AI大模型
如何用AI重塑你的工作流(一)
“可用”“有用”的讯飞星火认知大模型将亮相世界人工智能大会
彭博社:苹果Vision Pro曾测试VR手柄追踪方案
Zoom远程会议应用:AI培训需经用户授权
人工智能“Aria”现身 Opera浏览器100版本更新:新功能“标签岛”
金山办公:AI是重要的产品战略之一
苹果头显降临,AI虚拟人的救星还是流星?
OpenAI更新GPT-4等模型,新增API函数调用,价格最高降75%
北京市通用人工智能产业创新伙伴计划名单公布,京东科技入选“算力伙伴”
Win11 的画图应用将包含 Windows Copilot 的 AI 工具整合
WHEE功能介绍
全新“AI助手”!讯飞星火助手中心人机协作共创新生态
GPT-4使用混合大模型?研究证明MoE+指令调优确实让大模型性能超群
厂商陆续公布AI进展 完美世界游戏展示复合应用AI in GamePlay
马斯克嘲讽人工智能:机器学习本质就是统计学
XREAL Beam 投屏盒子正式发布:支持“可悬停 AR 空间屏”
酒店业将如何受益于人工智能的改变?
解决导航“最后50米”难题 高德地图升级AR步行导航找终点功能
WPS AI 官网上线:可申请体验官资格,支持 Windows、安卓端下载
加强能源消费绿色转型政策引导
OpenAI CEO 阿尔特曼到访日本,对全球 AI 协调合作表示乐观
生成式人工智能进入产业应用!但再“聪明”仍是工具,最终目的是服务于人
寻求能源转型最优解
NTU、上海AI Lab整理300+论文:基于Transformer的视觉分割最新综述出炉
MiracleVision视觉大模型功能介绍
财联社首档运用虚拟人技术播报栏目《AI半小时》今晚上线!敬请期待
GPT-4 模型架构泄露:包含 1.8 万亿参数、采用混合专家模型
让AI助手带您轻松愉快地享受写作之旅
国网辉南供电:无人机空中巡检 全力护航端午佳节
软银、淡马锡、沙特阿美突击入股,“协作机器人第一股”节卡股份:强敌环伺,持续失血是常态
Gartner发布中国企业人工智能趋势浪潮3.0
马斯克反讽人工智能AI炒作:“机器学习”本质就是统计
“技术+实践+生态”三箭齐发,京东方抢占物联网高地
印象笔记开放旗下“印象 AI”,可一键生成思维导图、写文章等
微软推出 LLaVA-Med AI 模型,可对医学病理案例进行分析
人工智能产业协同创新中心:全产业链资源在这里汇聚
谷歌推出新 AI 工具 Imagen Editor,一句话对图片二次创作
论文插图也能自动生成了,用到了扩散模型,还被ICLR接收
昌吉市利用无人机实现全天候河道动态巡检
 当前位置:
当前位置:  上一篇:
上一篇: 返回列表
返回列表