400 128 6709

行业新闻
 发布时间:2024-02-26
发布时间:2024-02-26 点击次数:
点击次数: 前段时间,AI大神Karpathy上线的AI大课,已经收获了全网15万次播放量。
当时还有网友表示,这2小时课程的含金量,相当于大学4年。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
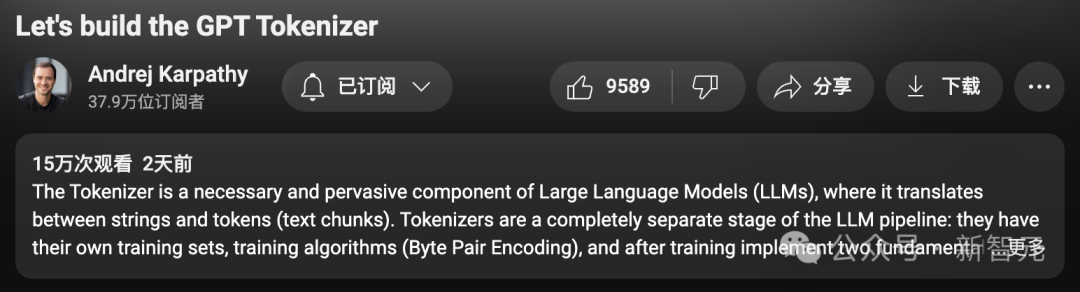
就在这几天,Karpathy又萌生了一个新的想法:
将2小时13分钟的“从头开始构建gpt分词器”视频内容转化为书中的章节或博客文章的形式,着重探讨“分词”这一主题。
具体步骤如下:
- 为视频添加字幕或解说文字。
- 将视频切割成若干带有配套图片和文字的段落。
- 利用大语言模型的提示工程技术,逐段进行翻译。
- 将结果输出为网页形式,其中包含指向原始视频各部分的链接。
更广泛地说,这样的工作流程可以应用于任何视频输入,自动生成各种教程的「配套指南」,使其格式更加便于阅读、浏览和搜索。
这听起来是可行的,但也颇具挑战。
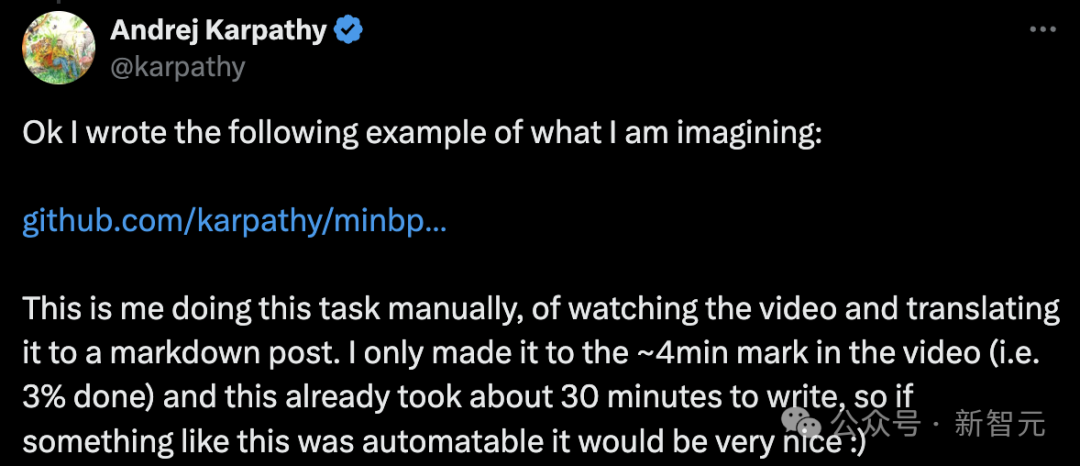
他在GitHub项目minbpe下,写了一个例子来阐述自己的想象。
地址:https://github.com/karpathy/minbpe/blob/master/lecture.md
Karpathy表示,这是自己手动完成的任务,即观看视频并将其翻译成markdown格式的文章。
「我只看了大约4分钟的视频(即完成了3%),而这已经用了大约30分钟来写,所以如果能自动完成这样的工作就太好了」。
接下来,就是上课时间了!
大家好,今天我们将探讨LLM中的「分词 」问题。
」问题。
遗憾的是,「分词」是目前最领先的大模型中,一个相对复杂和棘手的组成部分,但我们有必要对其进行详细了解。
因为LLM的许多缺陷可能归咎于神经网络,或其他看似神秘的因素,而这些缺陷实际上都可以追溯到「分词」。
字符级分词
那么,什么是分词呢?
事实上,在之前的视频《让我们从零开始构建 GPT》中,我已经介绍过分词,但那只是一个非常简单的字符级版本。
如果你去Google colab查看那个视频,你会发现我们从训练数据(莎士比亚)开始,它只是Python中的一个大字符串:
First Citizen: Before we proceed any further, hear me speak.All: Speak, speak.First Citizen: You are all resolved rather to die than to famish?All: Resolved. resolved.First Citizen: First, you know Caius Marcius is chief enemy to the people.All: We know't, we know't.
但是,我们如何将字符串输入LLM呢?
我们可以看到,我们首先要为整个训练集中的所有可能字符,构建一个词汇表:
# here are all the unique characters that occur in this textchars = sorted(list(set(text)))vocab_size = len(chars)print(''.join(chars))print(vocab_size)# !$&',-.3:;?ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz# 65
然后根据上面的词汇表,创建用于在单个字符和整数之间进行转换的查找表。此查找表只是一个Python字典:
stoi = { ch:i for i,ch in enumerate(chars) }itos = { i:ch for i,ch in enumerate(chars) }# encoder: take a string, output a list of integersencode = lambda s: [stoi[c] for c in s]# decoder: take a list of integers, output a stringdecode = lambda l: ''.join([itos[i] for i in l])print(encode("hii there"))print(decode(encode("hii there")))# [46, 47, 47, 1, 58, 46, 43, 56, 43]# hii there
一旦我们将一个字符串转换成一个整数序列,我们就会看到每个整数,都被用作可训练参数的二维嵌入的索引。
因为我们的词汇表大小为 vocab_size=65 ,所以该嵌入表也将有65行:
class BigramLanguageModel(nn.Module):def __init__(self, vocab_size):super().__init__()self.token_embedding_table = nn.Embedding(vocab_size, n_embd)def forward(self, idx, targets=None):tok_emb = self.token_embedding_table(idx) # (B,T,C)
在这里,整数从嵌入表中「提取」出一行,这一行就是代表该分词的向量。然后,该向量将作为相应时间步长的输入输入到Transformer。
使用BPE算法进行「字符块」分词
对于「字符级」语言模型的天真设置来说,这一切都很好。
但在实践中,在最先进的语言模型中,人们使用更复杂的方案来构建这些表征词汇。
具体地说,这些方案不是在字符级别上工作,而是在「字符块」级别上工作。构建这些块词汇表的方式是使用字节对编码(BPE)等算法,我们将在下面详细介绍该算法。
暂时回顾一下这种方法的历史发展,将字节级BPE算法用于语言模型分词的论文,是2019年OpenAI发表的GPT-2论文Language Models are Unsupervised Multitask Learners。

论文地址:https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf
向下翻到第2.2节「输入表示」,在那里他们描述并激励这个算法。在这一节的末尾,你会看到他们说:
词汇量扩大到50257个。我们还将上下文大小从512增加到1024个token,并使用512更大batchsize。
回想一下,在Transformer的注意力层中,每个token都与序列中之前的有限token列表相关联。
本文指出,GPT-2模型的上下文长度从GPT-1的512个token,增加到1024个token。
换句话说,token是 LLM 输入端的基本「原子」。
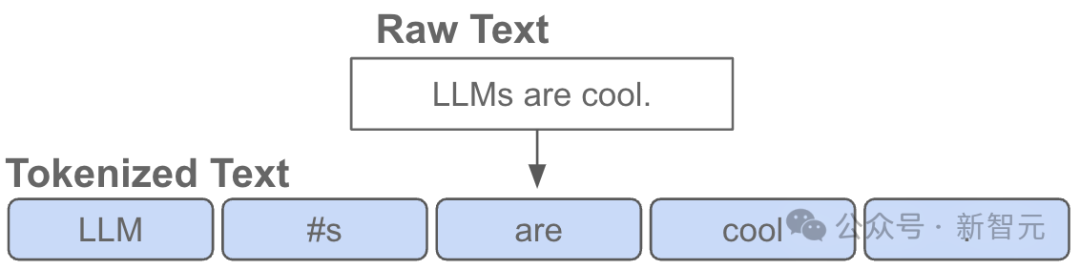
「分词」是将Python中的原始字符串,转换为token列表的过程,反之亦然。
还有一个流行的例子可以证明这种抽象的普遍性,如果你也去Llama 2的论文中搜索「token」,你将得到63个匹配结果。
比如,该论文声称他们在2万亿个token上进行了训练,等等。

论文地址:https://arxiv.org/pdf/2307.09288.pdf
 TTSMaker
TTSMaker
TTSMaker是一个免费的文本转语音工具,提供语音生成服务,支持多种语言。
 2275
查看详情
2275
查看详情

浅谈分词的复杂性
在我们深入探讨实现的细节之前,让我们简要地说明一下,需要详细了解「分词」过程的必要性。
分词是LLM中许多许多怪异问题的核心,我建议你不要忽略它。
很多看似神经网络架构的问题,实际上都与分词有关。这里只是几个例子:
- 为什么LLM不会拼写单词?——分词
- 为什么LLM不能执行超简单的字符串处理任务,比如反转字符串?——分词
- 为什么LLM在非英语语言(比如日语)任务中更差?——分词
- 为什么LLM不擅长简单的算术?——分词
- 为什么GPT-2在用Python编码时遇到了更多的问题?——分词
- 为什么我的LLM在看到字符串时突然停止?——分词
- 我收到的关于「trailing whitespace」的奇怪警告是什么?——分词
- 如果我问LLM关于「SolidGoldMagikarp」的问题,为什么它会崩溃?——分词
- 为什么我应该使用带有LLM的YAML而不是JSON?——分词
- 为什么LLM不是真正的端到端语言建模?——分词

我们将在视频的末尾,再回到这些问题上。
分词的可视化预览
接下来,让我们加载这个分词WebApp。
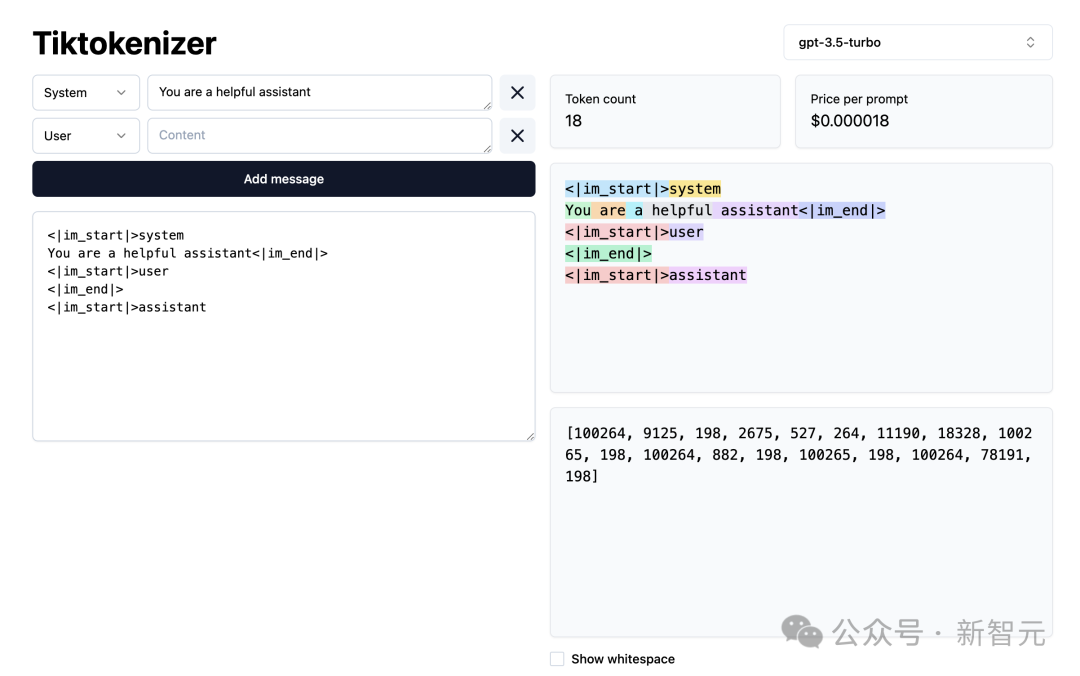
地址:https://tiktokenizer.vercel.app/
这个Web应用程序的优点是,分词在网络浏览器中实时运行,允许你轻松地在输入端输入一些文本字符串,并在右侧看到分词结果。
在顶部,你可以看到我们当前正在使用 gpt2 分词器,并且可以看到,这个示例中粘贴的字符串目前正在分词为 300个token。
在这里,它们用颜色明确显示出来:
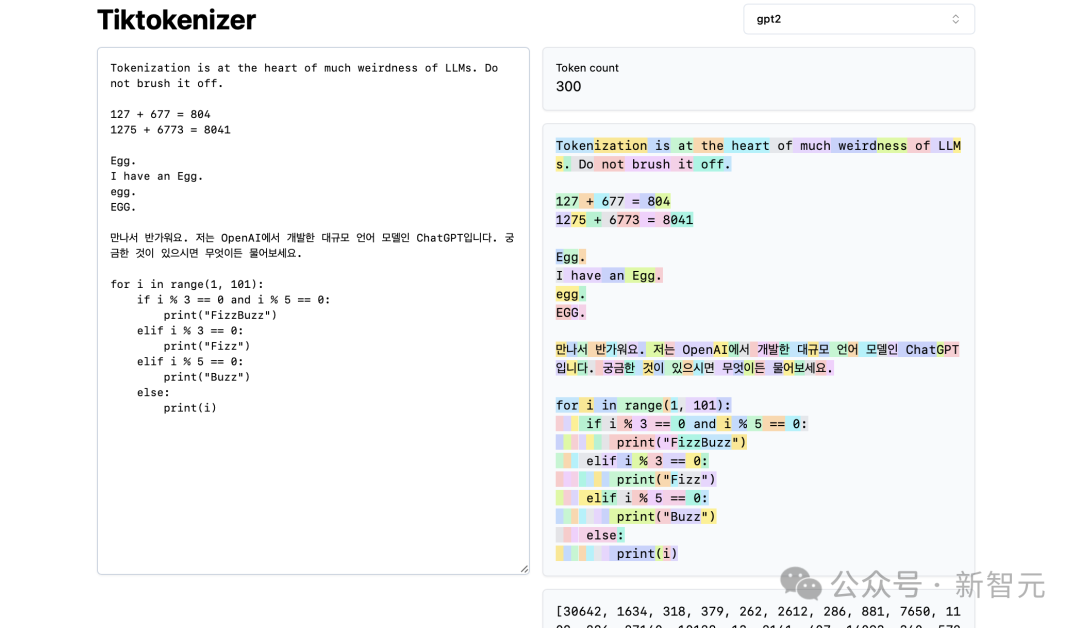
比如,字符串「Tokenization」编码到token30642,其后是token是1634。
token「is」(注意,这是三个字符,包括前面的空格,这很重要!)是318。
注意使用空格,因为它在字符串中是绝对存在的,必须与所有其他字符一起分词。但为了清晰可见,在可视化时通常会省略。
你可以在应用程序底部打开和关闭它的可视化功能。同样,token「at」是379,「the」是262,依此类推。
接下来,我们有一个简单的算术例子。
在这里,我们看到,分词器对数字的分解可能不一致。比如,数字127是由3个字符组成的token,但数字677是因为有2个token:6(同样,请注意前面的空格)和77。
我们依靠LLM来解释这种任意性。
它必须在其参数内部和训练过程中,了解这两个token(6和77实际上组合成了数字677)。
同样,我们可以看到,如果LLM想要预测这个总和的结果是数字804,它必须在两个时间步长内输出:
首先,它必须发出token「8」,然后是token「04」。
请注意,所有这些拆分看起来都是完全任意的。在下面的例子中,我们可以看到1275是「12」,然后「75」,6773实际上是三个token「6」、「77」、「3」,而8041是「8」、「041」。
(未完待续...)
(TODO:若想继续文字版的内容,除非我们想出如何从视频中自动生成)

网友表示,太好了,实际上我更喜欢阅读这些帖子,而不是看视频,更容易把握自己的节奏。

还有网友为Karpathy出谋划策:
「感觉很棘手,但使用LangChain可能是可行的。我在想是否可以使用whisper转录,产生有清晰章节的高级大纲,然后对这些章节块并行处理,在整体提纲的上下文中,专注于各自章节块的具体内容(也为每个并行处理的章节生成配图)。然后再通过LLM把所有生成的参考标记,汇编到文章末尾」。

有人为此还写了一个pipeline,而且很快便会开源。
以上就是干货满满!大神Karpathy两小时AI大课文字版第一弹,全新工作流自动把视频转成文章的详细内容,更多请关注其它相关文章!
# 在这里
# 网站商城线下推广方法
# 柳江区创新seo方法
# 深圳电子城网站优化
# 虚拟资源怎么做网站推广
# 营口搜索seo服务商
# 米哈游的营销推广怎么样
# seo的元素名称
# 南平推广网站
# 建设英文网站 论坛
# 惠州网站建设详细方案
# 让我们
# ai
# 可以看到
# 词汇表
# 开源
# 两小时
# 转成
# 文字版
# 大神
# 工作流
# llama
# langchain
# gpt
相关栏目:
【
行业新闻62819 】
【
科技资讯67470 】
相关推荐:
一文看懂被英伟达看中的九号机器人移动底盘
东软成立魔形科技研究院,积极布局大语言模型系统工程战略,迎接AI时代
苹果AI战略与微软谷歌大相径庭,到底是领先还是落后?
Meta Quest订阅服务每月7.99美元畅玩两款VR游戏应用
解决导航“最后50米”难题 高德地图升级AR步行导航找终点功能
QQ音乐业内率先推出「AI一起听」功能,领取你的AI听歌助手
AMD在AI方面奋起直追,与英伟达的差距缩小了吗?
苹果AIGC专利:可通过语音指令生成AR/VR虚拟场景
人工智能的变革之路:通过OpenAI的GPT-4漫游
一家 380 亿美元的数据巨头,要掀起企业「AI 化」革命
实践J*a开发,构建高性能的MongoDB数据迁移工具
如何提高集群协作效率?中外团队合作研发基于均值偏移的机器人队形控制策略
IBM 与 NASA 携手开源地理空间 AI 模型,促进气候科学研究进步
杀入生成式AI的亚马逊云科技,能否再次生成未来?
鹅厂机器狗抢起真狗「饭碗」!会撒欢儿做游戏,遛人也贼6
GPT-4使用混合大模型?研究证明MoE+指令调优确实让大模型性能超群
航拍无人机怎么选?大疆无人机盘点推荐
定义人工智能的十个关键术语
“思享荟”沙龙热议AIGC与元宇宙 复旦大学赵星畅谈深度数字化
在心理治疗中用VR技术,治疗成效显著提高
【搞事】时隔4年 谷歌更新安卓logo 机器人头更饱满了
丰田汽车研究院推出生成式人工智能汽车设计工具
“无人驾驶船”将首次亮相世界人工智能大会,下半年或开进上海迪士尼
令人惊叹!AI模型能够以iPhone照片为基础创作诗歌
明略科技发布免费开源TensorBoard.cpp,促进大型模型的预训练工作
盘古大模型3.0正式发布 AI开发正走向新“工业化开发模式”
斑马推出全新升级版思维机:以人工智能为核心的交互式学习体验
iPhone两秒出图,目前已知的最快移动端Stable Diffusion模型来了
AI新风口?首个高质量「文生视频」模型Zeroscope引发开源大战:最低8G显存可跑
人工智能和神经网络有什么联系与区别?
GPT-4 模型架构泄露:包含 1.8 万亿参数、采用混合专家模型
OpenAI更新GPT-4等模型,新增API函数调用,价格最高降75%
学界业界大咖探讨:AI对数字艺术创新的推动力
AI+游戏首度大范围公布实际应用成果,AI全面来临还有多远?
360发布数字安全和人工智能的强大结合:360安全大模型
英伟达推出 L40S GPU,AI 推理性能超过 A100 约 1.2 倍
ChatGPT设计出的第一个机器人来了!【附人工智能行业预测】
CharacterAI - 也许会成为会话人工智能的未来
谷歌将使用公开信息训练 AI 模型,构建更强大的自家产品
AI 作画工具 Midjourney 推出“pan”功能,可平移扩展图片外场景
视觉中国推出AI灵感绘图功能,付费后可在“合法合规前提下使用”
周鸿祎参加中美青年科技创新峰会,分享人工智能创新机遇
七大主流AI企业包括OpenAI、谷歌等联合承诺:引入水印技术,并允许第三方审核AI内容
世界人工智能大会中西部县域数字就业中心组团亮相
阿里云AI绘画创作大模型通义万相发布 已开启定向邀测
将上下文长度扩展到256k,无限上下文版本的LongLLaMA来了?
微盟宣布联合腾讯云共建行业大模型:加快激活AI大模型智能应用
“五年内人类程序员将消失”预言引争议,AI真的那么强大了吗?
美版贴吧8000小组自爆停摆!拒绝数据被谷歌OpenAI白嫖,CEO被网友骂翻:背刺第三方应用
“技术+实践+生态”三箭齐发,京东方抢占物联网高地
 当前位置:
当前位置:  上一篇:
上一篇: 返回列表
返回列表