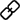400 128 6709

行业新闻
 发布时间:2023-10-17
发布时间:2023-10-17 点击次数:
点击次数: 几个月前,来自 KAUST(沙特阿卜杜拉国王科技大学)的几位研究者提出了一个名为 MiniGPT-4 的项目,它能提供类似 GPT-4 的图像理解与对话能力。
例如 MiniGPT-4 能够回答下图中出现的景象:「图片描述的是生长在冰冻湖上的一株仙人掌。仙人掌周围有巨大的冰晶,远处还有白雪皑皑的山峰……」假如你接着询问这种景象能够发生在现实世界中吗?MiniGPT-4 给出的回答是这张图片在现实世界中并不常见,并给出了原因。

短短几个月过去了,近日,KAUST 团队以及来自 Meta 的研究者宣布,他们将 MiniGPT-4 重磅升级到了 MiniGPT-v2 版本。

论文地址:https://arxiv.org/pdf/2310.09478.pdf
论文主页:https://minigpt-v2.github.io/
Demo: https://minigpt-v2.github.io/
 Voicepods
Voicepods
Voicepods是一个在线文本转语音平台,允许用户在30秒内将任何书面文本转换为音频文件。
 142
查看详情
142
查看详情

具体而言,MiniGPT-v2 可以作为一个统一的接口来更好地处理各种视觉 - 语言任务。同时,本文建议在训练模型时对不同的任务使用唯一的识别符号,这些识别符号有利于模型轻松的区分每个任务指令,并提高每个任务模型的学习效率。
为了评估 MiniGPT-v2 模型的性能,研究者对不同的视觉 - 语言任务进行了广泛的实验。结果表明,与之前的视觉 - 语言通用模型(例如 MiniGPT-4、InstructBLIP、 LLaVA 和 Shikra)相比,MiniGPT-v2 在各种基准上实现了 SOTA 或相当的性能。例如 MiniGPT-v2 在 VSR 基准上比 MiniGPT-4 高出 21.3%,比 InstructBLIP 高出 11.3%,比 LLaVA 高出 11.7%。
下面我们通过具体的示例来说明 MiniGPT-v2 识别符号的作用。
例如,通过加 [grounding] 识别符号,模型可以很容易生成一个带有空间位置感知的图片描述:

通过添加 [detection] 识别符号,模型可以直接提取输入文本里面的物体并且找到它们在图片中的空间位置:

框出图中的一个物体,通过加 [identify] ,可以让模型直接识别出来物体的名字:
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
 通过加 [refer] 和一个物体的描述,模型可以直接帮你找到物体对应的空间位置:
通过加 [refer] 和一个物体的描述,模型可以直接帮你找到物体对应的空间位置:

你也可以不加任何任务识别符合,和图片进行对话:

模型的空间感知也变得更强,可以直接问模型谁出现在图片的左面,中间和右面:

MiniGPT-v2 模型架构如下图所示,它由三个部分组成:视觉主干、线 性投影层和大型语言模型。
性投影层和大型语言模型。

视觉主干:MiniGPT-v2 采用 EVA 作为主干模型,并且在训练期间会冻结视觉主干。训练模型的图像分辨率为 448x448 ,并插入位置编码来扩展更高的图像分辨率。
线性投影层:本文旨在将所有的视觉 token 从冻结的视觉主干投影到语言模型空间中。然而,对于更高分辨率的图像(例如 448x448),投影所有的图像 token 会导致非常长的序列输入(例如 1024 个 token),显着降低了训练和推理效率。因此,本文简单地将嵌入空间中相邻的 4 个视觉 token 连接起来,并将它们一起投影到大型语言模型的同一特征空间中的单个嵌入中,从而将视觉输入 token 的数量减少了 4 倍。
大型语言模型:MiniGPT-v2 采用开源的 LLaMA2-chat (7B) 作为语言模型主干。在该研究中,语言模型被视为各种视觉语言输入的统一接口。本文直接借助 LLaMA-2 语言 token 来执行各种视觉语言任务。对于需要生成空间位置的视觉基础任务,本文直接要求语言模型生成边界框的文本表示以表示其空间位置。
多任务指令训练
本文使用任务识别符号指令来训练模型,分为三个阶段。各阶段训练使用的数据集如表 2 所示。

阶段 1:预训练。本文对弱标记数据集给出了高采样率,以获得更多样化的知识。
阶段 2:多任务训练。为了提高 MiniGPT-v2 在每个任务上的性能,现阶段只专注于使用细粒度数据集来训练模型。研究者从 stage-1 中排除 GRIT-20M 和 LAION 等弱监督数据集,并根据每个任务的频率更新数据采样比。该策略使本文模型能够优先考虑高质量对齐的图像文本数据,从而在各种任务中获得卓越的性能。
阶段 3:多模态指令调优。随后,本文专注于使用更多多模态指令数据集来微调模型,并增强其作为聊天机器人的对话能力。
最后,官方也提供了 Demo 供读者测试,例如,下图中左边我们上传一张照片,然后选择 [Detection] ,接着输入「red balloon」,模型就能识别出图中红色的气球:

感兴趣的读者,可以查看论文主页了解更多内容。
以上就是MiniGPT-4升级到MiniGPT-v2了,不用GPT-4照样完成多模态任务的详细内容,更多请关注其它相关文章!
# ai
# 所示
# 更高
# 阿卜杜拉
# 出了
# 本田
# 高出
# 可以直接
# 图中
# 多模
# 升级到
# llama
# 数据
# 濮阳网站seo关键词排名优化
# 慈溪外语网站建设哪家好
# 潍坊网站推广威薪hfqjwl下拉
# 怎样能学好seo
# 武汉seo工具
# 威海短视频seo工具
# seo有什么证件
# 灰色敏感词seo
# 绥化seo公司首选11火星
# 丰都网站建设团队招聘
相关栏目:
【
行业新闻62819 】
【
科技资讯67470 】
相关推荐:
苹果机器学习关键人物 Ali Farhadi 离职,回归 AI2 担任 CEO
中国电信AI能力通过国家级金融领域权威认证并荣膺AI国际头部竞赛冠军
靠游戏更靠AI 英伟达成唯一首季度两位数增长的公司
Unity 内测 Safe Voice 服务,利用 AI 自动识别玩家不当聊天内容
技术如何使人变得懒惰?
日入400万,第一批AI骗子已上岗
OpenAI已向中国申请注册“GPT-5”商标,此前已在美国提交申请
大厂出品!这个AI网站太顶了,所有功能免费用
学界业界大咖探讨:AI对数字艺术创新的推动力
《自然》杂志拒绝刊登人工智能生成的图片和视频
你大脑中的画面,现在可以高清还原了
人工智能即将进入Windows:企业准备好安全策略设置了吗?
朱民:普通人炒股炒不过机器人是很正常的 AI已经能理解市场情绪
航拍无人机怎么选?大疆无人机盘点推荐
消息称苹果 iPhone 15 系列健康应用将深度融合 AI 技术
当一个网站的内容被 AI 完全接管
视觉中国推出AI灵感绘图功能,付费后可在“合法合规前提下使用”
网易加速行业AI大模型应用,将覆盖100多个应用场景
盘古大模型3.0正式发布 AI开发正走向新“工业化开发模式”
用人工智能技术,亚马逊为用户生成产品评论摘要,帮助他们轻松选购
售价14.99万起!小米汽车部分信息疑遭AI曝光,内部人士回应:网传图片明显经过处理,不可轻信
陈根教授:离人形机器人时代还有10年吗?
微软在 Bing 和 Edge 浏览器中拓展网购服务,帮用户选购心仪产品
新华社联合北大发布AI大模型评测:安全可靠成重点,360智脑表现优异
BLIP-2、InstructBLIP稳居前三!十二大模型,十六份榜单,全面测评「多模态大语言模型」
西班牙小鲜肉*视频在网上疯传,本人发文澄清:是AI换脸的假视频!
调研海尔智家:AI名,家电命?
Adobe旗下Illustrator引入生成式AI工具Firefly
张朝阳与陆川谈AI:ChatGPT是鹦鹉学舌思维,不可能取代人类 | 把脉AI大模型
业内领先 四川大学华西第四医院甲状腺乳腺外科成功进入手术机器人时代
聚焦WAIC|AI技术支撑大模型探索未来
AI 助手 Copilot 上线,微软 Win11 Dev 预览版 Build 23493 发布
AI 模型 Stable Diffusion 升级:正常生成五指、图像更逼真
讯飞听见会写“会议摘要”功能全面升级,AI更懂你的关注点
2025VR&AR显示技术峰会视频解析: 歌尔光学展示最新一代VR/AR光学模组
首届全国体育人工智能大会在首都体育学院召开
“风乌”气象大模型科学家团队:用AI预报极端天气未来不是梦!
WPS AI 官网上线:可申请体验官资格,支持 Windows、安卓端下载
扎克·施奈德新片《月球叛军》曝剧照 机器人首度现身
尼康尼克尔 Z 180-600mm f/5.6-6.3 VR 镜头发布,12499 元
当TS遇上AI,会发生什么?
明略科技发布免费开源TensorBoard.cpp,促进大型模型的预训练工作
智能公司为何纷纷投身机器人领域?
「社交达人」GPT-4!解读表情、揣测心理全都会
2025VR&AR显示技术峰会展示歌尔光学最新一代光学模组
煤电“三改联动”需多措联动
云深处与昇腾CANN携手合作:开设ROS四足机器狗开发训练营
一家 380 亿美元的数据巨头,要掀起企业「AI 化」革命
鉴智机器人发布基于地平线征程5的标准视觉感知产品
参考封面|人工智能“淘金热”
 当前位置:
当前位置:  上一篇:
上一篇: 返回列表
返回列表