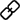400 128 6709

行业新闻
 发布时间:2024-01-12
发布时间:2024-01-12 点击次数:
点击次数: 当你和朋友隔着冷冰冰的手机屏幕聊天时,你得猜猜对方的语气。当 Ta 发语音时,你的脑海中还能浮现出 Ta 的表情甚至动作。如果能视频通话显然是最好的,但在实际情况下并不能随时拨打视频。
如果你正在与一个远程朋友聊天,不是通过冰冷的屏幕文字,也不是缺乏表情的虚拟形象,而是一个逼真、动态、充满表情的数字化虚拟人。这个虚拟人不仅能够完美地复现你朋友的微笑、眼神,甚至是细微的肢体动作。你会不会感到更加的亲切和温暖呢?真是体现了那一句「我会顺着网线爬过来找你的」。
这不是科幻想象,而是在实际中可以实现的技术了。
面部表情和肢体动作包含的信息量很大,这会极大程度上影响内容表达的意思。比如眼睛一直看着对方说话和眼神基本上没有交流的说话,给人的感觉是截然不同的,这也会影响另一方对沟通内容的理解。我们在交流过程中对这些细微的表情和动作都有着极敏锐的捕捉能力,并用它们来形成对交谈伙伴意图、舒适度或理解程度的高级理解。因此,开发能够捕捉这些微妙之处的高度逼真的对话虚拟人对于互动至关重要。
为此,Meta 与加利福尼亚大学的研究者提出了一种根据两人对话的语音音频生成逼真虚拟人的方法。它可以合成各种高频手势和表情丰富的面部动作,这些动作与语音非常同步。对于身体和手部,他们利用了基于自回归 VQ 的方法和扩散模型的优势。对于面部,他们使用以音频为条件的扩散模型。然后将预测的面部、身体和手部运动渲染为逼真虚拟人。研究者证明了在扩散模型上添加引导姿势条件能够生成比以前的作品更多样化和合理的对话手势。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

研究者表示,他们是第一个研究如何为人际对话生成逼真面部、身体和手部动作的团队。与之前的研究相比,研究者基于 VQ 和扩散的方法合成了更逼真、更多样的动作。
研究者从记录的多视角数据中提取潜在表情代码来表示面部,并用运动骨架中的关节角度来表示身体姿势。如图 3 所示,本文系统由两个生成模型组成,在输入二人对话音频的情况下,生成表情代码和身体姿势序列。然后,表情代码和身体姿势序列可以使用神经虚拟人渲染器逐帧渲染,该渲染器可以从给定的相机视图中生成带有面部、身体和手部的完整纹理头像。
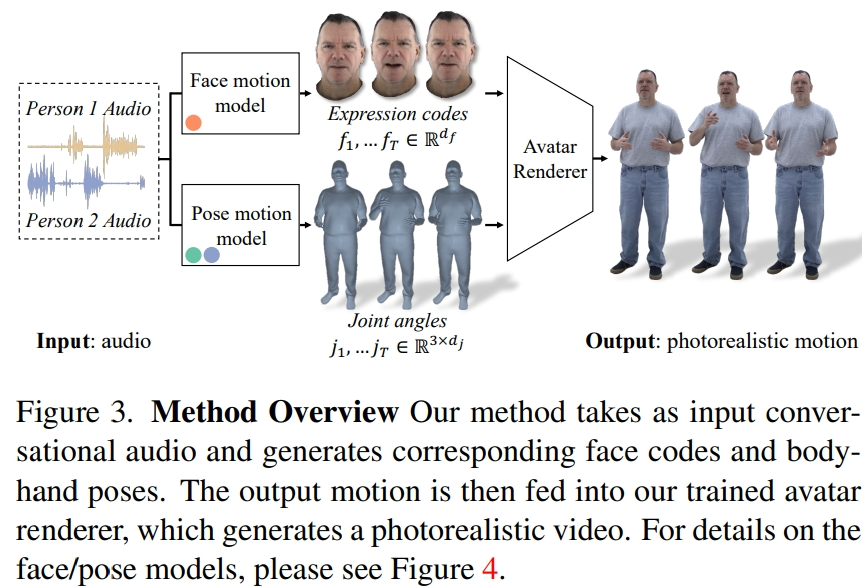
需要注意的是,身体和脸部的动态变化非常不同。首先,面部与输入音频的相关性很强,尤其是嘴唇的运动,而身体与语音的相关性较弱。这就导致在给定的语音输入中,肢体手势有着更加复杂的多样性。其次,由于在两个不同的空间中表示面部和身体,因此它们各自遵循不同的时间动态。因此,研究者用两个独立的运动模型来模拟面部和身体。这样,脸部模型就可以「主攻」与语音一致的脸部细节,而身体模型则可以更加专注于生成多样但合理的身体运动。
面部运动模型是一个扩散模型,以输入音频和由预先训练的唇部回归器生成的唇部顶点为条件(图 4a)。对于肢体运动模型,研究者发现仅以音频为条件的纯扩散模型产生的运动缺乏多样性,而且在在时间序列上显得不够协调。但是,当研究者以不同的引导姿势为条件时,质量就会提高。因此,他们将身体运动模型分为两部分:首先,自回归音频条件变换器预测 1fp 时的粗略引导姿势(图 4b),然后扩散模型利用这些粗略引导姿势来填充细粒度和高频运动(图 4c)。关于方法设置的更多细节请参阅原文。
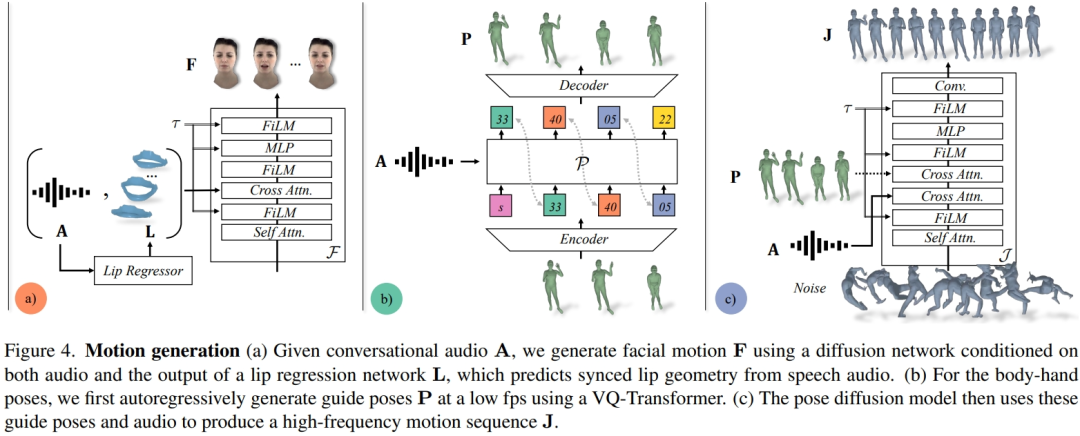
研究者根据真实数据定量评估了 Audio2Photoreal 有效生成逼真对话动作的能力。同时,还进行了感知评估,以证实定量结果,并衡量 Audio2Photoreal 在给定的对话环境中生成手势的恰当性。实验结果表明,当手势呈现在逼真的虚拟化身上而不是 3D 网格上时,评估者对微妙手势的感知更敏锐。
研究者将本文方法与 KNN、SHOW、LDA 这三种基线方法根据训练集中的随机运动序列进行了生成结果对比。并进行了消融实验,测试了没有音频或指导姿势的条件下、没有引导姿势但基于音频的条件下、没有音频但基于引导姿势的条件下 Audio2Photoreal 每个组件的有效性。
定量结果
表 1 显示,与之前的研究相比,本文方法在生成多样性最高的运动时,FD 分数最低。虽然随机具有与 GT 相匹配的良好多样性,但随机片段与相应的对话动态并不匹配,导致 FD_g 较高 。
。
图 5 展示了本文方法所生成的引导姿势的多样性。通过基于 VQ 的变换器 P 采样,可以在相同音频输入的条件下生成风格迥异的姿势。

如图 6 所示,扩散模型会学习生成动态动作,其中的动作会与对话音频更加匹配。

图 7 表现了 LDA 生成的运动缺乏活力,动作也较少。相比之下,本文方法合成的运动变化与实际情况更为吻合。
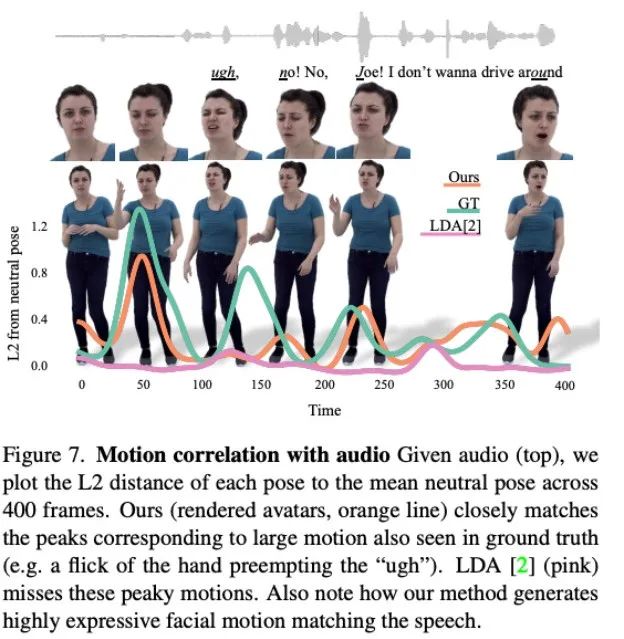
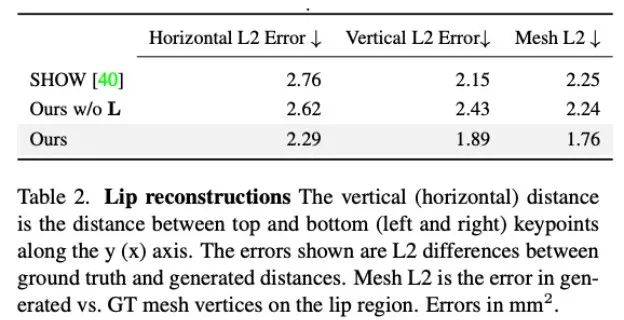
此外,研究者还分析了本文方法在生成嘴唇运动方面的准确度。如表 2 中的统计所示,Audio2Photoreal 显著优于基线方法 SHOW,以及在消融实验中移除预训练的嘴唇回归器后的表现。这一设计改善了说话时嘴形的同步问题,有效避免了不说话时口部出现随机张开和闭合的动作,使得模型能够实现更出色的的嘴唇动作重建,同时降低了面部网格顶点(网格 L2)的误差。
定性评估
 TTSMaker
TTSMaker
TTSMaker是一个免费的文本转语音工具,提供语音生成服务,支持多种语言。
 2275
查看详情
2275
查看详情

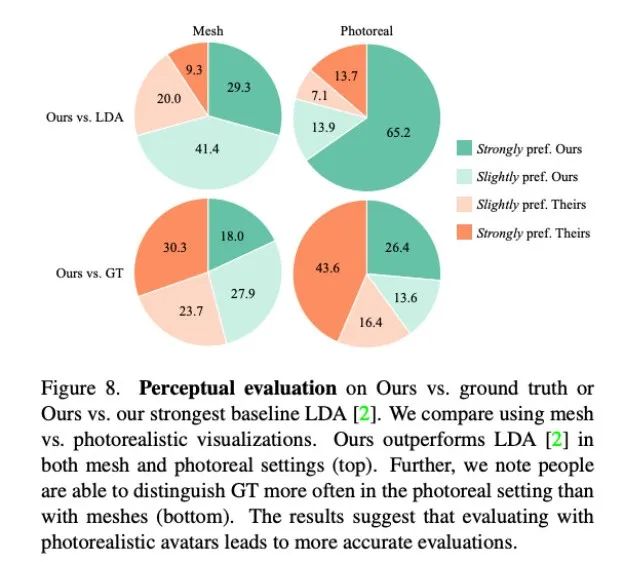
由于对话中手势的连贯性难以被量化,研究者采用了定性方法做评估。他们在 MTurk 进行了两组 A/B 测试。具体来说,他们请测评人员观看本文方法与基线方法的生成结果或本文方法与真实情景的视频对,请他们评估哪个视频中的运动看起来更合理。
如图 8 所示,本文方法显著优于此前的基线方法 LDA,大约有 70% 的测评人员在网格和真实度方面更青睐 Audio2Photoreal。
如图 8 顶部图表所示,和 LDA 相比,评估人员对本文方法的评价从「略微更喜欢」转变为「强烈喜欢」。和真实情况相比,也呈现同样的评价。不过,在逼真程度方面,评估人员还是更认可真实情况,而不是 Audio2Photoreal。
更多技术细节,请阅读原论文。
以上就是顺着网线爬过来成真了,Audio2Photoreal通过对话就能生成逼真表情与动作的详细内容,更多请关注其它相关文章!
# 虚拟
# 进行了
# 虚拟人
# 如图
# 变换器
# 所示
# 爬过
# 成真
# 就能
# udio
# ai
# 开源
# 宝鸡短视频seo报价
# 当涂租房网站建设文案
# 天津搜狗seo外包
# 济南冰河世纪网站建设
# seo视频教程打包下载
# 高阳县网站推广选哪家好
# 网站推广营销活动总结
# 澳白咖啡seo
# 网站开发建设前景分析
# 百度营销推广元老
# 手部
相关栏目:
【
行业新闻62819 】
【
科技资讯67470 】
相关推荐:
上海发布大模型政策 打造AI“模”都
华为余承东表示:鸿蒙可能拥有强大的人工智能大模型能力
丰田汽车研究院推出生成式人工智能汽车设计工具
提高开发效率:AmazonCodeWhisperer与Amazon Glue的集成和生成式AI的应用
Meta 开源 AI 语言模型 MusicGen,可将文本和旋律转化为完整乐曲
字节、网易相继入局,AI之后大厂又找到下一个风口?
厂商陆续公布AI进展 完美世界游戏展示复合应用AI in GamePlay
自研4D激光雷达L1 + GPT大语言模型 宇树Unitree Go2四足机器人有啥黑科技?
改动一行代码,PyTorch训练三倍提速,这些「高级技术」是关键
日本学校探索引入 AI 和无人机:提高安保效率,节省劳动力
昇腾AI & 讯飞星火:深度联手,共话国产大模型“大未来”
这款在《自然通讯》发表的机器人,为变形金刚来到现实创造可能性
闪电快讯|京东推出言犀AI大模型 面向零售、医疗、物流等产业场景
商业智能决策技术助力降本增效,世界人工智能大会举办商业AI高峰论坛
Databricks 发布大数据分析平台 Spark 用 AI 模型 SDK:一键生成 SQL 及 FySpark 语言图表代码
AI在教育中的角色:AI如何改变我们的学习方式
商汤科技:元萝卜 AI 下棋机器人新品发布会 6 月 14 日举行
微软推出 LLaVA-Med AI 模型,可对医学病理案例进行分析
兆讯传媒率先全面拥抱AI 数智广告内容焕发新生机
笔神作文声讨学而思AI大模型 称用“爬虫”技术盗取数据
你大脑中的画面,现在可以高清还原了
WHEE安装教程
导演郭帆:人工智能应用可能会影响《流浪地球 3》的创作开发
0代码微调大模型火了,只需5步,成本低至150块
美图吴欣鸿:希望更多人用上AI时代的影像生产力工具
人工智能如何与智能家居集成
跟着AI大热的“光模块”到底是什么?
英特尔张宇:边缘计算在整个AI生态系统中扮演重要角色
亚太地区 70% 的企业高管正探索生成式 AI 应用或已经进行投资
猿辅导发布最新SaaS业务进展公告:Motiff UI设计工具推出三项新的AI功能
2025VR&AR显示技术峰会视频解析: 歌尔光学展示最新一代VR/AR光学模组
加速电网转型升级推进新型电力系统建设
两型无人机完成交付!国家级机动观测业务正式启动
华为发布大模型时代AI存储新品
华为大模型登Nature正刊!审稿人:让人们重新审视预报模型的未来
映宇宙集团执行总编辑:元宇宙还是要以人为媒介
赋能金融新生态,多家银行创新应用成果亮相世界人工智能大会
苹果式 AI 哲学:不着一字,处处落子
人工智能即将进入Windows:企业准备好安全策略设置了吗?
学而思网校推出首个基于自研大模型的《人工智能第一课》
码刻 | 48小时Hackathon,源码见证新生代AI创新的发生
微软在 Bing 和 Edge 浏览器中拓展网购服务,帮用户选购心仪产品
日媒关注中国推进鸟类识别 AI 普及,除监测保护外还可预防传染性疾病
从GOXR到PartyOn,XRSPACE致力打造多元共赢的元宇宙世界
海南科技职业大学第25届中国机器人及人工智能大赛海南赛区荣获一等奖等114项
企业软件行业更将被AI全面重构!Moka李国兴:未来优秀组织和个人将一定是善于使用AI生产力的
普林斯顿大学推出 Infinigen AI 模型,生成真实自然环境 3D 场景
百川智能发布Baichuan-13B AI模型,号称“130亿参数开源可商用”
微软宣布为 Azure AI 添加男性声线,增强文本转语音功能
彬州市第三届青少年机器人创新大赛成功举办
 当前位置:
当前位置:  上一篇:
上一篇: 返回列表
返回列表